Buy vs. Build LLMs: How to Choose the Right Choice for Your Needs
Confused between buying pre-trained language models (LLMs) or building your own? Explore the advantages of both options and get expert guidance to make the right choice for your specific needs and goals
Introduction
The decision between buying or building Large Language Models (LLMs) can be challenging. This article aims to help you make an informed choice based on your needs and goals.
Fine-tuned LLMs
As the name suggests, fine-tuned LLMs have undergone a further training phase, and users can access the final product. Fine-tuning allows developers to take advantage of the pre-trained model's general language understanding and enhance it for their specific use cases, saving time and resources compared to training a language model from scratch.
Advantages of Pre-trained LLMs
One of the popular pre-trained LLMs is ChatGPT, developed by OpenAI, offering a subscription plan with access to advanced features like the GPT-4 model and a code interpreter. The advantages of pre-trained LLMs include continuous performance improvements and the ability to handle various complex tasks such as text summarization, content generation, code generation, sentiment analysis, and chatbots.
Benefits of Pre-trained LLMs
Pre-trained LLMs offer convenience, saving time and cost, as building your own language model can be expensive and time-consuming. Integration is made easy with APIs provided by services like ChatGPT, and prompt engineering allows users to enhance output quality without modifying the underlying model.
Open-Source LLMs (Build LLMs)
In contrast, open-source LLMs allow users to train and fine-tune the model to suit specific needs. The entire code and structure of these LLMs are publicly available, providing greater flexibility and customization options.
Examples of Open-Source LLMs
Some examples of open-source LLMs include Google PaLM, LLaMA (released by Meta), Falcon (developed by Technology Innovation Institute), and OpenAI Text-Davinci-003
Benefits of Open-Source LLMs
Open-source LLMs require more technical knowledge and computational resources to train but offer greater control over data, model architecture, and enhanced privacy. Collaboration among developers is promoted, leading to innovative training approaches and new applications.
Factors to Consider in Your Decision
When deciding between pre-trained and open-source LLMs, several factors come into play:
Budget
Pre-trained models are more cost-effective as they eliminate the need for training from scratch, while open-source LLMs require more resources.
Time
Pre-trained models are readily available for use, saving time compared to training open-source LLMs.
Privacy
Open-source LLMs provide more control over sensitive data and offer better privacy measures.
Expertise
Using open-source LLMs requires specialized knowledge in NLP and machine learning, whereas pre-trained models are more user-friendly.
Customization
Open-source LLMs offer greater freedom for customization, allowing users to tailor the model to their specific needs.
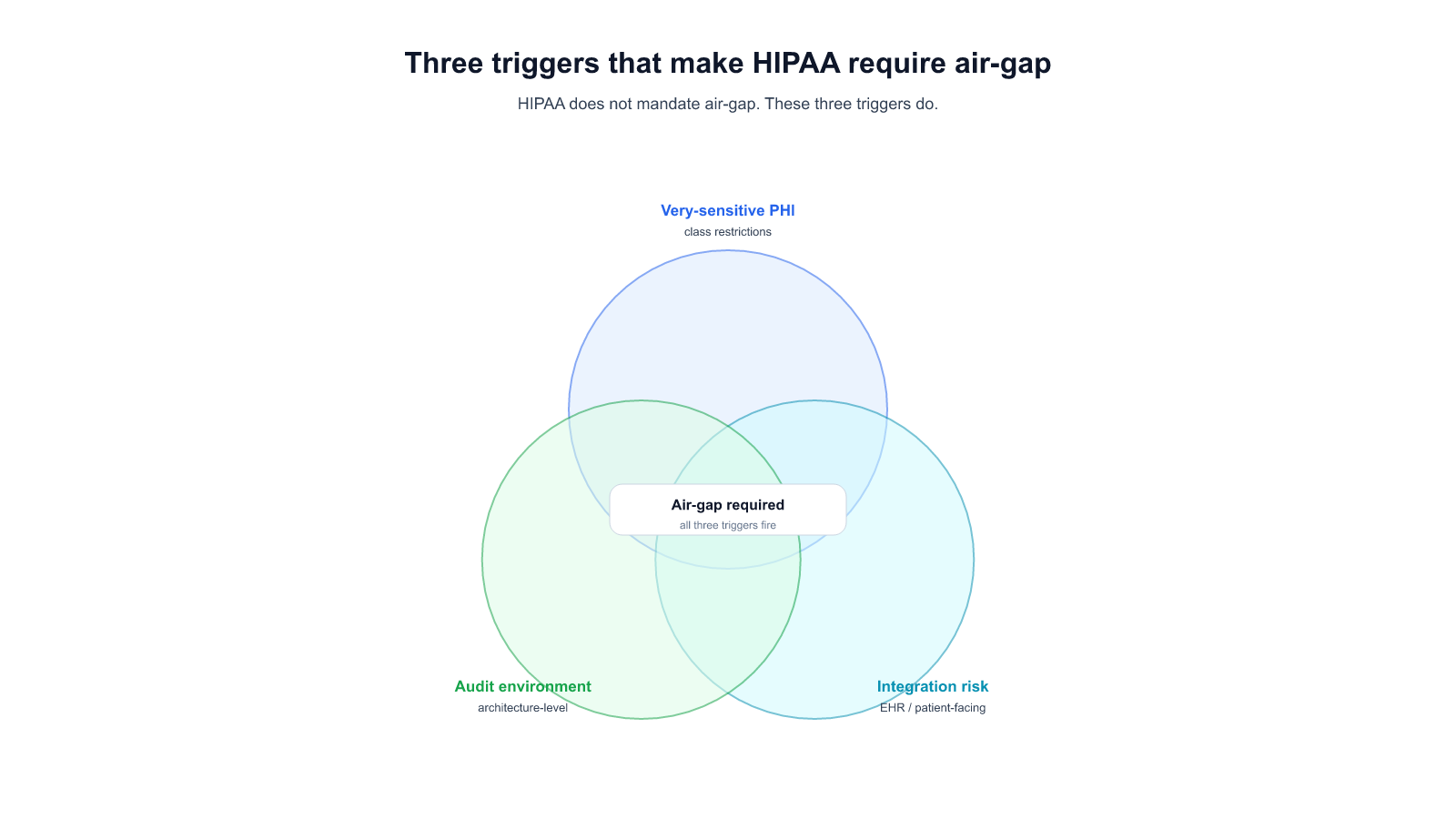
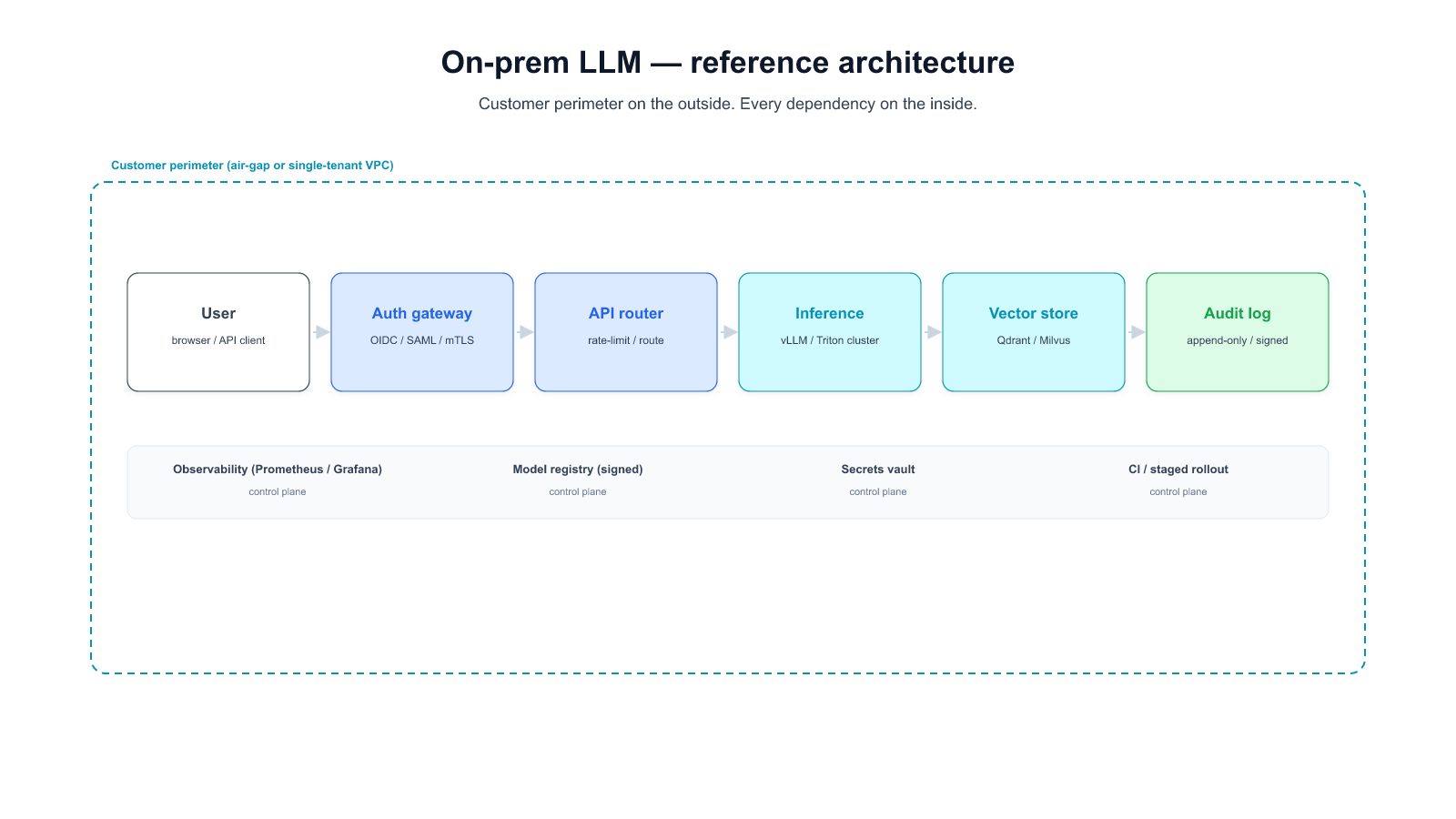
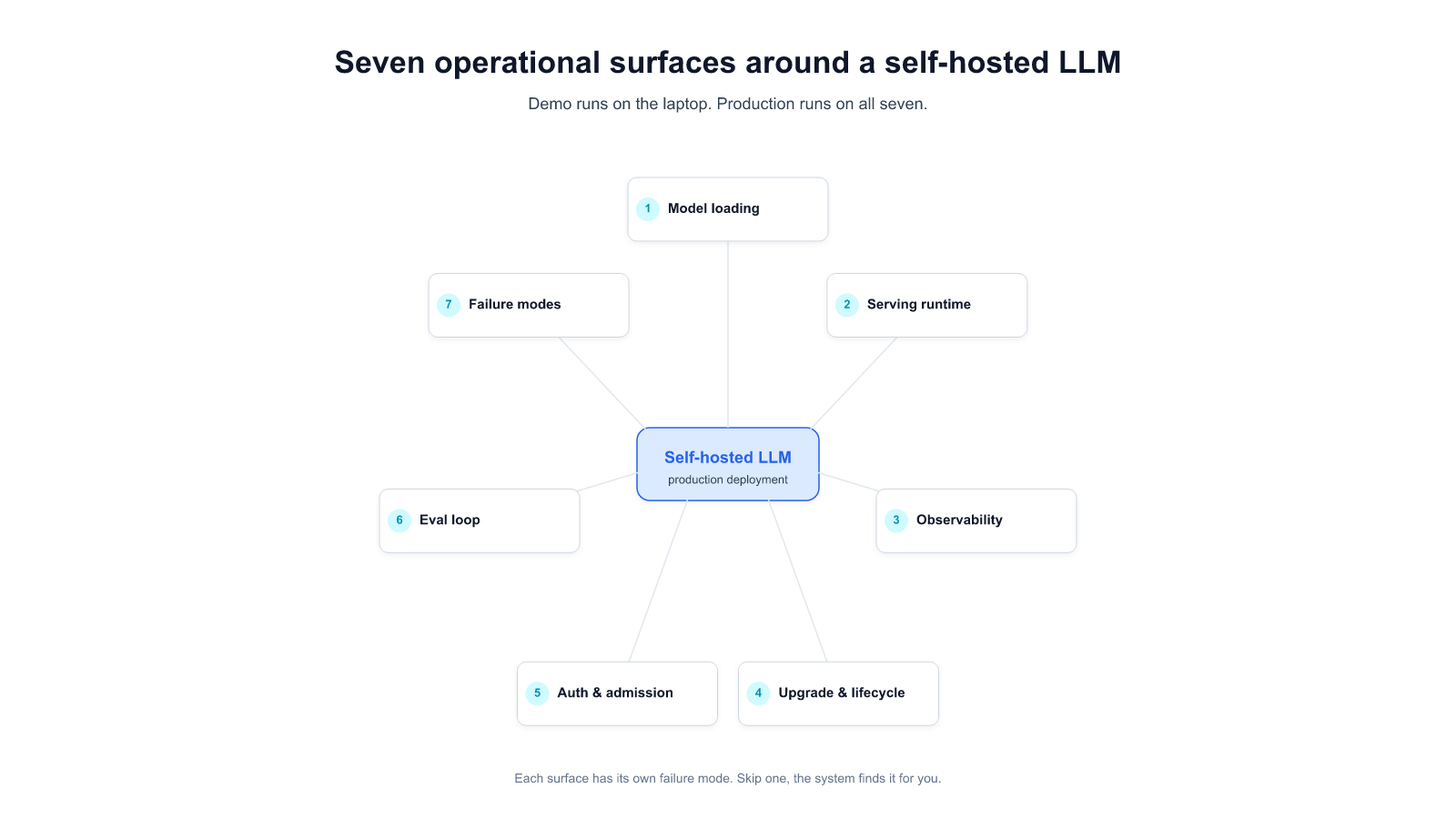
Allganize offers the essential infrastructure to construct your personalized app, complete with robust security measures, efficient control management, and your exclusive on-premise LLM. We understand that some businesses require on-premise solutions to comply with regulations or address specific privacy concerns. Our Alli LLM Ops empowers enterprises with the flexibility to process data locally, ensuring compliance and providing an added layer of security.
Overall Quality
Both types of LLMs deliver high performance, but open-source models excel when trained for specific tasks.
Making Your Final Decision
Ultimately, the choice between pre-trained and open-source LLMs depends on your budget, time, expertise, and specific use case. If you have the resources and want maximum customization, open-source LLMs are ideal. However, if convenience and constant improvement are essential, pre-trained LLMs are the way to go.
Remember to carefully assess your situation and goals before deciding on the best LLM option.
To explore Allganize's LLM solutions for your enterprise, visit our website and book a consultation with our team of experts today!