
도구를 연결하는 것과 도구가 대화하게 만드는 것
6개 에이전트 체인이 프로덕션에서 침묵한 이유, 재실행이 예외가 아닌 설계 원칙인 이유, MCP "연결됐다"와 "작동한다"의 차이 — 금융·제조·IT 4개 현장에서 드러난 에이전트 운영 성숙도 4단계.
— 에이전트 워크플로우가 현장에서 부딪히는 벽들, 그리고 운영 가능한 에이전트의 조건
6개 에이전트를 연결한 워크플로우가 데모에서 완벽하게 작동했다. 프로덕션에 올리자 서브에이전트가 보낸 결과를 메인 에이전트는 한 건도 받지 못했다.
로컬에서 되는 것과 프로덕션에서 되는 것은 완전히 다른 일이었다.
지난 4편에서는 에러 로그 없이 조용히 실패하는 RAG와 에이전트 품질 문제를 다뤘다. 이번 글에서는 한 단계 위의 문제를 다룬다 — 에이전트가 서로를 부를 때, 에이전트가 도구를 쓸 때, 그리고 에이전트가 "알아서" 하면 안 될 때 생기는 일.
PoC에서는 나타나지 않는다. 프로덕션에서만 터진다.
서브에이전트가 보낸 결과를 메인은 한 건도 받지 못했다
금융 계열사 A그룹은 공통 업무 에이전트를 구축 중이었다.
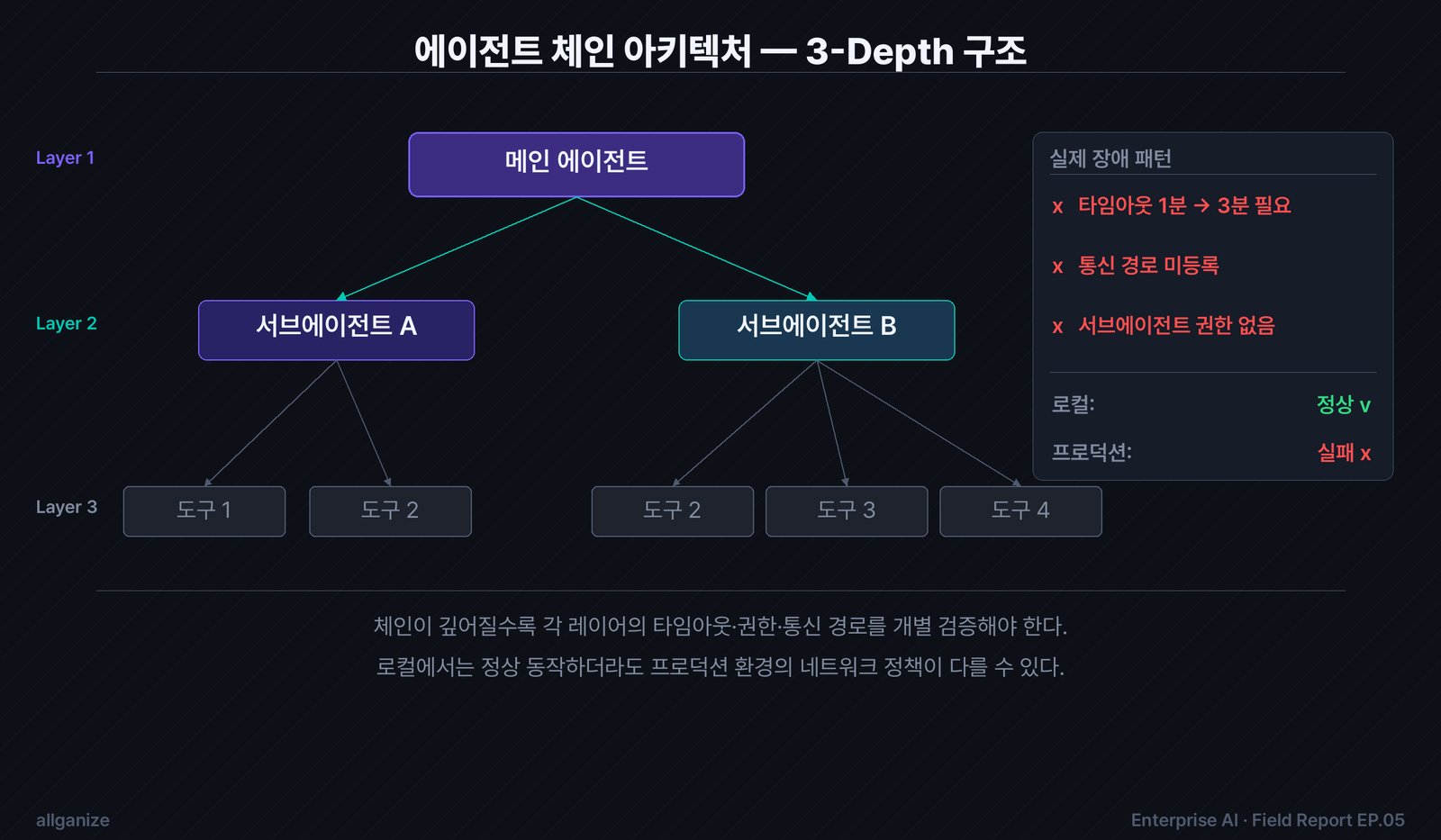
이번 목표는 멀티에이전트 워크플로우 구축이었다. 메인 에이전트가 서브에이전트를 호출하고, 서브에이전트가 다시 도구를 실행하는 3단계 깊이(3-depth) 체인. 업무별로 분리된 서브에이전트들이 각자의 도구를 갖고 메인의 지시를 받아 처리하는 구조.
로컬 테스트: 정상. 스테이징: 정상. 시연 준비 완료.
그리고 프로덕션(US/JA 서버)에 올리자 — 결과 0건.
데모 현장에서, 아무것도 돌아오지 않았다
메인 에이전트는 서브에이전트에게 지시를 보냈다. 서브에이전트는 도구를 실행했다. 그런데 결과가 메인으로 돌아오지 않았다. 워크플로우 전체가 작동하는 것처럼 보였지만 — 최종 결과는 비어 있었다.
원인은 두 가지였다.
첫 번째: 프로덕션 환경의 내부 통신 경로 설정이 달랐다. 중간 서브에이전트의 툴 리스트에 하위 에이전트가 등록되지 않은 버그였다. 로컬과 스테이징에서는 설정이 동일했고, 프로덕션에서만 이 경로가 빠져 있었다.
두 번째: 타임아웃.
기본 타임아웃이 지나치게 짧았다. 3-depth 체인에서 메인이 서브를 부르고, 서브가 다시 도구를 실행하고, 결과가 역순으로 올라오는 총 시간 — 기본값으로는 절대적으로 부족했다.
"sub에이전트 도느라 타임아웃 종료가 많이 나네욥!!"
타임아웃을 체인 깊이에 맞게 연장하는 것으로 수정됐다.

2초가 1분이 된 이유 — 환경 구조의 문제
로컬에서 2초 안에 끝나던 체인이 프로덕션에서 왜 1분이 넘었는지 — 이 질문이 중요하다.
단순히 서버가 느린 것이 아니다. 세 가지 오버헤드가 겹쳤다.
첫째, 네트워크 레이턴시의 곱셈 효과. 로컬에서는 에이전트 간 통신이 루프백(loopback) 인터페이스로 이뤄진다 — 사실상 0ms. 프로덕션에서는 각 에이전트가 별도 컨테이너에 격리되어 내부 네트워크로 통신한다. 단계 하나에 수십 ms가 추가된다. 3-depth 체인에서 각 단계가 2회 통신한다면 — 레이턴시만으로 이미 상당한 오버헤드가 쌓인다. 시작에 불과하다.
둘째, 컨테이너 오버헤드. 각 서브에이전트는 자체 실행 환경을 갖는다. 메인이 서브를 호출할 때 컨테이너가 워밍업(warm-up) 상태라면 첫 응답까지 수 초가 걸린다. 로컬에서는 프로세스가 이미 메모리에 올라와 있다.
셋째, 토큰 처리의 환경별 차이. 프로덕션 GPU 리소스 할당이 로컬 실험 환경과 달랐다. 같은 요청이라도 추론 시간이 달라진다. 서브에이전트가 복잡한 지시를 받을수록 — 토큰 처리량이 직접 레이턴시에 반영된다.
이 세 오버헤드가 3-depth 체인에서 순차적으로 쌓인다. 결과: 로컬에서는 문제없던 체인이 프로덕션에서 기본 타임아웃을 훌쩍 넘겼다. 기본 타임아웃은 짧았고, 체인은 침묵했다.
멀티에이전트 시스템 연구에 따르면 조정 오버헤드는 에이전트 수가 늘수록 급격히 커진다 — 5개 에이전트에서 200ms이던 오버헤드가 50개 에이전트에서 2초 이상으로 보고된 사례가 있다 [7]. 에이전트 수와 동일한 공식으로 단정하긴 어렵지만, 깊이(depth)가 늘어도 구조상 유사한 누적 효과가 나타난다.
타임아웃보다 더 깊은 문제
통신 경로 버그와 타임아웃을 고쳤다. 워크플로우가 돌아갔다. 그런데 다른 현장에서 유사한 구조를 구축하면서 더 근본적인 난제가 드러났다.
서로 다른 에이전트를 워크플로우로 연결했을 때 — 이전 실행의 상태를 공유하는 것 자체가 구조적 문제다.
멀티턴 대화에서 메인 에이전트가 서브에이전트를 호출할 때, 서브에이전트는 메인의 대화 히스토리를 얼마나 알아야 하는가? 서브에이전트가 실행 중에 실패했을 때, 메인은 어디서부터 다시 시작해야 하는가? 서브에이전트 A의 결과가 서브에이전트 B의 입력이 되는 경우, 상태는 누가 갖고 있는가?
한 엔지니어의 반응은 솔직했다.
"해결이 쉽지는 않을 것 같아요."
단일 에이전트의 도구 호출은 비교적 단순하다. 에이전트가 에이전트를 부르는 체인은 다른 차원의 문제다. 타임아웃 값 하나, 통신 경로 설정 하나, 상태 공유 방식 하나가 전체 체인을 침묵시킨다. 그리고 로컬에서는 이 벽이 보이지 않는다.
비슷한 구조의 3-depth 워크플로우를 도입한 다른 금융사에서도 타임아웃 이슈가 반복됐다. 한 고객사만의 문제가 아니다.

재실행은 예외가 아니라 운영 설계다
금융사 H의 AI 담당팀에서 에이전트 운영 중에 질의가 들어왔다. 에이전트가 프롬프트에 명시된 사항을 끝까지 실행하지 않는다는 내용이었다. 팀 내 논의 끝에 "실패 시 재실행하는 방식"이 현실적인 운영 전략이라는 결론에 이르렀다.
이 결론을 처음 들으면 "버그를 고쳐야지 재실행이 답이냐"는 반응이 나온다. 맞다. 그런데 이 결론에 에이전트 운영의 핵심 전환점이 압축되어 있다.
전통 소프트웨어와 에이전트의 근본적 차이
전통 소프트웨어는 결정론적이다. 같은 입력 → 같은 출력. 이것이 당연한 전제다. 시스템이 "간헐적으로 작동하지 않는다"는 것은 곧 버그다. 고쳐야 한다.
LLM 기반 에이전트는 본질적으로 비결정론적이다. 같은 프롬프트에 같은 도구가 연결되어 있어도 — 실행 완결성이 보장되지 않는다. 온도(temperature)를 0으로 설정해도 마찬가지다. NAACL 2025 연구에 따르면 "어떤 LLM도 완벽한 결정론이나 높은 답변 일관성에 근접하지 못했다" — greedy sampling 설정에서도 동일 입력의 반복 실행은 서로 다른 결과를 낸다 [1]. 소형 LLM 128회 반복 실험에서 특정 질문의 오류율이 89%에 달한 케이스도 있다 [1].
이것은 버그가 아니다. LLM의 작동 방식이다.
이 비결정성을 받아들이는 순간 — 운영 설계가 바뀐다.
재시도(retry), 자동 검증(validation), 부분 결과 활용(partial result). 이것들이 에러 처리의 예외 케이스가 아니라 운영 설계의 기본 단위가 된다.
전통 소프트웨어 개발에서는 "retry 로직은 네트워크 오류에만 쓴다"는 암묵적 규칙이 있다. LLM 에이전트에서는 retry가 정상 운영 흐름의 일부다.
금융사 H가 겪은 장애 — 그리고 어떻게 수습했나
실제 운영에서 발생한 사건을 순서대로 재구성하면 이렇다.
Incident: 에이전트가 다중 단계 문서 요약 작업을 실행 중에 멈췄다. 중간 단계까지 완료하고 — 멈췄다. 에러 메시지는 없었다. 타임아웃 로그도 없었다. 에이전트는 응답을 반환하지 않은 채 세션을 종료했다.
Root Cause: 후반 단계에서 에이전트가 참조해야 할 컨텍스트 길이가 모델의 처리 한계에 근접했다. 동시에 해당 시점에 응답 토큰 샘플링의 확률적 선택이 "다음 단계로 진행"보다 "완료 선언"으로 수렴했다. 두 요인 모두를 대상으로 운영 설계를 전환했다.
Resolution: 팀은 세 가지를 바꿨다.
첫째, 단계 간 체크포인트 저장. 각 단계 완료 시 중간 결과를 외부 스토리지에 기록했다. 이전에는 에이전트가 내부 메모리만 사용했다. 이제 앞 단계까지 완료된 결과가 남아 있으면 — 다음 단계부터 재시작할 수 있다.
둘째, 단계별 완료 검증. 각 단계 출력에 "이 단계가 완료됐는가"를 확인하는 별도 검증 프롬프트를 추가했다. 에이전트의 자기 보고(self-report)를 믿지 않는 것이다. ReliabilityBench 연구가 보여주듯 — 벤치마크 대비 프로덕션 신뢰성은 20-40% 과다 추정된다 [4]. 에이전트가 "완료됐다"고 말해도 실제로는 부분 완료인 경우가 있다.
셋째, 재실행을 운영 정책으로 명문화. "실패 시 전체 재실행"이 아니라 "체크포인트 이후부터 재실행"이 표준 복구 절차가 됐다. 이것은 개별 버그 수정이 아니다 — 에이전트 운영의 설계 원칙이다.
Insight: 금융사 H가 "재실행 방식으로 해야 할 것 같습니다"라는 결론에 이른 순간 — 이 팀은 에이전트 운영의 첫 번째 패러다임 전환을 마친 것이다. PoC에서 "에이전트가 완벽하게 작동한다"고 믿었던 팀이 가장 먼저 부딪히는 벽이 여기다. τ-bench 측정에 따르면 pass@1 기준 60%를 달성한 에이전트도 복수 실제 시도에서 일관성은 25%에 불과하다 [4]. 일회 성공과 반복 안정성은 다른 이야기다.
한 가지 더. 재시도를 설계할 때 "재시도 스톰(retry storm)"을 피해야 한다. 여러 에이전트가 동시에 실패한 작업을 재시도하면 — 캐스케이드 장애로 번진다. 서킷 브레이커와 하드 타임아웃 예산, 그리고 상관 ID 기반 로깅이 실용적 최소 요건이다 [9].
MCP 연결과 동작은 다른 말이다
제조사 E는 3편에서 H100 2장 환경에서 Qwen 모델을 전환한 고객사다. 이번에는 에이전트에 MCP 서버를 연동하려 했다.
MCP(Model Context Protocol)는 LLM 에이전트가 외부 도구와 통신하는 표준 방식이다. 2024년 11월 Anthropic이 제안했다. 2025년 4월 OpenAI가 채택했고, 2025년 12월 Linux Foundation 산하 AAIF(Agentic AI Foundation)로 거버넌스가 이전됐다. 현재 SDK 월간 다운로드 9,700만 건 이상, PulseMCP 레지스트리 기준 5,500개 이상의 서버가 등록되어 있다 [2]. "대부분의 표준이 10년 걸리는 것을 1년 만에 달성"했다는 평가도 있다 [2].
제조사 E는 자체 데이터 파이프라인을 MCP 서버로 래핑해서 에이전트에 연결하려 했다. 연결은 됐다. 그런데 에이전트가 MCP 서버를 호출하면 — 결과를 쓸 수 없었다.
Response is not a valid tool result
"연결됐다"와 "작동한다"는 다른 말이다
원인은 output shape 불일치였다.
MCP Integration Node가 기대하는 응답 형식이 있다. 내부 MCP 서버가 실제로 반환하는 형식이 있다. 두 형식이 달랐다. 인터페이스 스펙이 변경되면서 외부 노드가 기대하는 output schema와 어긋났다.
수정됐다. 그러나 근본 문제는 남았다. MCP 스펙 자체의 output schema가 느슨하다 [3]. 구현체마다, 서버마다, 버전마다 실제 응답 형식이 미묘하게 다르다. "MCP를 쓴다"는 것과 "MCP 서버 간에 데이터가 정확히 오간다"는 것은 다른 이야기다.
표준이 있어도 왜 깨지는가 — MCP 생태계의 맥락
5,500개 이상의 MCP 서버가 등록되어 있다는 수치를 보면 — "표준이 정착됐다"는 인상을 준다. 그런데 CData의 분석은 다르게 읽는다 [2]. 서버 수는 채택의 지표가 아니다. 실제 프로덕션 채택의 강력한 지표는 원격(Remote) MCP 서버 증가율이다 — 2025년 5월 이후 약 4배 증가.
그리고 Zuplo 보고서가 지적한 과제들 [3]:
MCP가 도구 연동의 표준 경로를 만들었지만 — 표준이 있다는 것과 실제 구현이 표준을 정확히 따른다는 것은 다른 이야기다.
도구가 늘어날수록 정합 이슈가 급증한다
같은 패턴이 다른 현장에서도 나타났다.
또 다른 프로젝트에서는 에이전트가 쓰는 도구들 사이에 파일 경로 형식 자체가 달랐다. 한쪽 도구는 파일을 해시값으로 참조했다. 다른 쪽 도구는 파일명으로 참조했다. 파일명에 띄어쓰기가 포함되면 추가로 깨졌다.
# 도구 A가 반환하는 파일 참조
{"file_id": "a3f8b2d1e4c7..."} # 해시 기반
# 도구 B가 기대하는 파일 참조
{"file_path": "/data/documents/document_sample.pdf"} # 파일명 기반
각 도구가 독립적으로 개발됐다. I/O 포맷을 통일하지 않았다. 각각을 단독으로 테스트했을 때는 문제가 없었다.
에이전트 워크플로우에 연결하고 나서야 터졌다.
output shape, 파일 경로 포맷, 인코딩 방식, 에러 응답 구조 — 이 "보이지 않는 인터페이스"들이 실제 운영에서 가장 많은 시간을 잡아먹는다.
여기서 하나만 기억하면 된다. MCP 서버를 연결하기 전에, 두 서버의 응답 형식을 나란히 놓고 diff를 확인하라. 단독 테스트가 통과해도 인터페이스 호환성은 별도로 검증해야 한다. 연결 후 에러로 발견하는 것보다 연결 전 schema 비교가 훨씬 빠르다. 제조사 E가 Response is not a valid tool result를 프로덕션에서 처음 만난 이유가 여기 있다.
도구 연결에 이틀이 걸린다. 도구들이 제대로 대화하게 만드는 데 두 달이 걸린다.
에이전트 앞에 '인박스'를 놓다
IT서비스사 I는 PMO(프로젝트 관리 사무소) 업무 자동화 프로젝트를 시작했다. 여러 시스템에서 프로젝트 현황을 수집하고, 리스크를 감지하고, 관련 담당자에게 알리고, 다음 액션을 제안하는 — 자율형(autonomous) 에이전트였다.
기술적으로 구현 가능했다. 에이전트는 도구들을 연결하고, 데이터를 읽고, 결과를 생성할 수 있었다.
그런데 현장에서 "에이전트가 알아서 하면 안 되는 영역"이 예상보다 훨씬 많았다.
어떤 액션이 문제였나
초기 설계에서 에이전트는 세 가지 액션을 자율적으로 수행했다.
첫째, 리스크 감지 후 담당자에게 알림 발송. 리스크 분류 기준이 에이전트의 판단에 따랐고 — 오판 시 의도하지 않은 수신자에게 불필요한 알림이 발송됐다.
둘째, 일정 슬리피지(slippage) 감지 후 상위 리포팅. 에이전트가 프로젝트 지연을 감지하고 상위 보고에 자동으로 기록했다. 실제 지연이 아닌 데이터 업데이트 지연을 지연으로 해석한 케이스였다.
셋째, 다음 액션 제안을 작업 추적 시스템에 자동 등록. 에이전트가 제안한 액션이 이미 진행 중인 작업과 중복됐다.
세 케이스 모두 에이전트가 틀렸다기보다 — 에이전트가 알 수 없는 맥락이 있었다. 조직 내 커뮤니케이션 관행, 데이터 입력 딜레이, 이미 진행 중인 비공식 논의. 에이전트는 시스템에 기록된 것만 본다.
Inbox 설계 — 무엇을 어떻게 넣었나
결과: 에이전트 앞단에 Agent Inbox 시스템을 설계했다.
개념은 단순하다 — 에이전트가 행동을 취하기 전에 그 행동 제안을 "인박스"에 올리고, 사람이 승인하면 실행한다. 그런데 실제 설계에서 세부 사항이 중요했다.
승인 단위: 에이전트의 모든 액션이 승인 대상이 되면 — 자동화의 의미가 없다. IT서비스사 I는 승인 단위를 "불가역(irreversible) 액션"으로 한정했다. 알림 발송, 외부 시스템 기록, 상위 보고 업데이트. 데이터 수집과 분석은 에이전트가 자율로 수행한다.
비동기 승인: 담당자가 인박스를 즉시 확인하지 않을 수 있다. 승인 대기 중인 액션의 타임아웃을 설정했다 — 일정 시간 내 응답 없으면 해당 액션은 다음 사이클에서 재평가한다. LangGraph의 Dynamic/Async Interrupt 패턴이 이 구조를 지원한다 [6].
거절 시 학습: 담당자가 제안을 거절할 때 이유를 입력한다. 에이전트는 이 피드백을 다음 판단에 반영한다 — "이 PM은 외부 알림 발송 전에 직접 확인을 선호한다"는 맥락이 축적된다.
예외 처리: 긴급 상황에서 담당자가 인박스를 확인하기 전에 에이전트가 즉시 실행해야 하는 경우가 있다. 에이전트가 "긴급"으로 분류한 케이스는 짧은 시간 내 응답이 없으면 자동 실행으로 전환되는 룰이 추가됐다.
Human-in-the-loop는 한계가 아니다
처음 이 소식을 들으면 "그럼 자동화가 아니잖아"라는 반응이 나온다.
다시 생각해볼 필요가 있다.
자율형 에이전트가 100%의 정확도로 모든 케이스를 올바르게 처리한다면 — Human-in-the-loop는 불필요한 오버헤드다. 그런데 현실에서 에이전트의 정확도가 100%인 케이스는 없다. 특히 조직 내 의사결정이 개입되는 업무에서는.
Agent Inbox 모델에서 에이전트는 여전히 핵심 작업을 수행한다. 정보 수집, 데이터 통합, 리스크 패턴 감지, 액션 후보 생성. 사람이 하던 시간의 대부분을 줄인다. 사람은 판단에만 집중한다.
이것은 에이전트의 한계를 인정한 것이 아니다. 에이전트가 잘하는 것(정보 처리, 패턴 감지)과 사람이 해야 하는 것(최종 판단, 맥락 고려)을 구분한 운영 설계다.
LangGraph의 HITL 설계 원칙은 명확하다 [6]: "개입은 누락되거나 모호한 정보 감지 시에만 트리거되어야 한다." 모든 액션에 사람이 개입하는 것이 아니다 — 에이전트가 스스로 "이건 내가 판단하기 어렵다"고 인식하는 구조를 만드는 것이다.
에이전트의 자율성은 기술 문제가 아니라 운영 설계 문제다. "어디까지 자동으로 할 것인가"는 모델의 성능이 아니라 — 업무 프로세스와 조직 문화가 결정한다.
Human-in-the-loop는 에이전트의 한계가 아니라 운영 성숙의 출발점이다.
에이전트 운영 성숙도 — 4단계
네 가지 현장에서 반복되는 패턴이 있다. 에이전트 운영이 단계를 밟는다는 것이다.
대부분의 팀은 1단계에서 "에이전트가 작동한다"고 판단하고 프로덕션에 올린다.

Gartner는 2027년까지 에이전트 프로젝트의 40%가 실패할 것으로 예측한다 [5]. 국내 기업 데이터는 이미 그 방향을 가리키고 있다 — 도입 기업의 38.1%가 기대에 못 미친다고 답했다 [8].
1단계(연결)는 "연결이 됐다"는 것을 확인하는 단계다. MCP 등록, API 응답, 기본 도구 호출. PoC에서 할 수 있는 것. 여기서 멈추면 — 제조사 E의 Response is not a valid tool result가 된다.
2단계(정합)부터가 실제 운영의 시작이다. 도구들이 서로 올바른 형식으로 데이터를 주고받는가. 체인 전체가 프로덕션 환경에서 타임아웃 없이 완결되는가. 에러가 발생했을 때 체인 어디서 멈췄는지 알 수 있는가. A그룹의 타임아웃 이슈는 여기서 터진 문제다 — 로컬에서는 보이지 않는다.
3단계(신뢰)는 비결정성을 설계에 내재화하는 단계다. "에이전트가 완벽하게 작동한다"는 전제를 버리고, "에이전트가 실패할 수 있다는 것을 알고 복구한다"는 설계로 전환한다. 재시도 로직, 중간 결과 저장, 부분 완료 시 처리 방식. 금융사 H가 체크포인트 저장과 단계별 검증을 추가한 것이 이 전환이다. 이 단계에 도달해야 프로덕션에 올릴 수 있다.
4단계(자율)는 기술이 아니라 조직이 준비되어야 한다. "에이전트가 어디까지 자율적으로 행동해도 되는가"라는 질문은 모델의 정확도가 아니라 조직의 리스크 허용도와 프로세스 설계가 답한다. IT서비스사 I의 Inbox 설계가 그 답이었다 — 불가역 액션만 승인 대상으로 한정하고, 비동기 승인과 예외 처리 룰을 설계에 내재화했다.
아키텍처 선택은 복잡도를 결정한다
에이전트 구조를 선택할 때 — 복잡도가 높을수록 각 단계에 도달하는 데 더 많은 시간이 걸린다.

3-depth 이상의 체인은 상태 관리가 필수다. 그리고 이것이 현재 대부분의 에이전트 프레임워크에서 가장 미완성된 영역이다. 오케스트레이터 + 전문 에이전트 풀 구조는 복잡도 자체는 높지만 — 타임아웃 리스크를 오케스트레이터 레벨에서 관리할 수 있고, 외부 상태 저장소를 통해 상태 공유 문제를 명시적으로 설계할 수 있다.
어느 구조가 정답인가보다 — 지금 팀이 몇 단계에 있는가가 먼저다. 2단계에서 4단계 아키텍처를 선택하면 복잡도만 높아지고 운영 성숙도는 올라가지 않는다.
에이전트 플랫폼에 물어봐야 할 5가지
에이전트 플랫폼을 평가하거나 도입 검토 중이라면 — 기능 리스트보다 이 5가지 질문의 답을 먼저 들어야 한다.
1. "서브에이전트 체인의 최대 깊이(depth)는 몇 단계까지 지원합니까? 각 단계의 타임아웃은 어떻게 설정됩니까?"
2-depth와 3-depth는 지원 방식이 근본적으로 다르다. 기본 타임아웃이 얼마인지, 단계별로 독립적으로 설정 가능한지 확인해야 한다. 기본값이 짧은 플랫폼에서 3-depth 체인을 돌리면 — 데모에서야 알게 된다.
2. "도구 간 I/O 포맷 불일치가 발생했을 때, 플랫폼 레벨에서 변환(transform) 레이어를 제공합니까?"
output shape 불일치는 도구마다, 서버마다, 버전마다 발생한다. 매번 수동으로 파싱 코드를 작성하는 구조라면 — 도구 수가 늘어나는 순간부터 유지보수가 불가능해진다.
3. "에이전트가 중간에 실패했을 때, 부분 결과를 보존하고 재시도하는 메커니즘이 있습니까?"
"재시도하면 아마 됩니다"가 운영의 정상 상태라는 것을 받아들였다면 — 재시도가 처음부터 전체를 다시 돌리는 방식인지, 중간 체크포인트에서 재시작할 수 있는지가 결정적으로 다르다. 긴 체인이 마지막 단계에서 실패했을 때의 차이다.
4. "Human-in-the-loop 승인 워크플로우를 에이전트 파이프라인에 삽입할 수 있습니까?"
Agent Inbox 같은 구조를 만들려면 — 플랫폼이 에이전트 실행 중간에 "일시 정지 → 사람 확인 → 재개" 흐름을 지원해야 한다. 비동기 승인, 타임아웃 시 기본 동작, 거절 시 분기 처리. 이것들이 플랫폼 기능으로 있는지 아니면 직접 구현해야 하는지 확인해야 한다.
5. "프로덕션 환경에서 에이전트의 도구 호출 성공률과 평균 응답 시간을 모니터링할 수 있습니까?"
4편에서 언급했듯 프로덕션 AI 에이전트 중 성숙한 모니터링을 갖춘 비율은 낮다. 에이전트 워크플로우에서 모니터링은 더 어렵다 — 단일 요청이 아니라 체인 전체의 성공/실패를 추적해야 하기 때문이다. 어느 단계에서 타임아웃이 났는지, 어느 도구의 output shape이 틀렸는지, 재시도가 몇 번 발생했는지 — 이 데이터 없이는 운영 성숙도를 올릴 수 없다. 특히 "에이전트 기반 호출은 성공했지만 목표를 달성하지 못한" 케이스는 일반 에러 지표에도 잡히지 않는다 [4].
이 5가지 중 3개 이상에 명확한 답이 없다면 — 그 플랫폼은 에이전트 "연결"은 되지만 "운영"은 준비되지 않은 것이다.
5편을 마치며 — 도구와 도구 사이의 벽
에이전트를 운영하는 것은 도구와 도구 사이의 보이지 않는 벽을 하나씩 허무는 일이다. 이번 편의 네 현장은 그 벽이 타임아웃·비결정성·output shape·자율 범위라는 서로 다른 면으로 나타난 사례였다. PoC에서는 보이지 않고, 프로덕션에서만 터진다.
에이전트 운영 성숙도 4단계(연결→정합→신뢰→자율)에서 — 지금 당신의 팀은 어디에 있는가. 그 답이 에이전트를 프로덕션에 올릴 수 있는 시점을 결정한다.
다음 편에서는 PoC가 끝나고 운영이 시작된 "Day 91"의 첫 장애를 다룬다. 운영 성숙도를 갖춘 팀이 — 오히려 갖췄기 때문에 — 만나게 되는 사건들과, 그 순간 올거나이즈 엔지니어링이 함께 해결한 방식.
이 글의 사례들은 온프레미스 AI 구축 엔지니어링 팀의 운영 경험에서 추출했습니다. 고객사명과 담당자명은 모두 익명입니다.
운영을 함께 설계할 팀이 필요하신가요?
올거나이즈는 금융·제조·공공·IT서비스 현장에서 온프레미스 AI의 도입 검토 → 운영 전환 → 장기 운영 파트너십을 하나의 흐름으로 설계해 왔습니다. 멀티에이전트 워크플로우 구축과 MCP 정합, 그리고 PoC 이후의 운영 성숙도 4단계 설계 경험을 기반으로, 지금 팀이 서 있는 지점부터 이야기를 시작할 수 있습니다.
출처
[1] "Evaluation of LLMs Should Not Ignore Non-Determinism," NAACL 2025, ACL Anthology — greedy sampling 설정에서도 LLM 비결정성 확인; "The Non-Determinism of Small LLMs," arXiv, 2025년 9월 — 소형 LLM 128회 반복 실험, 특정 케이스 오류율 89% (1차 출처: NAACL 공식, arXiv)
[2] "The State of MCP — Adoption, Security & Production Readiness," Zuplo, 2025-2026 — MCP SDK 월간 다운로드 9,700만 건+, PulseMCP 5,500개+ 서버; "2026: The Year for Enterprise-Ready MCP Adoption," CData, 2026 — Linux Foundation AAIF 이관 (T2)
[3] "The State of MCP," Zuplo, 2025-2026 — 도구 과노출, 컨텍스트 창 한계, 시장 파편화 위험 지적; "2026: Enterprise-Ready MCP," CData, 2026 — output schema 느슨한 정의, 구현체별 편차 (T2)
[4] "How Do LLMs Fail In Agentic Scenarios?," arXiv, 2025년 12월 — pass@1 60% 에이전트의 실제 일관성 25%, 벤치마크 90% → 프로덕션 70-80%; "ReliabilityBench," arXiv, 2026년 1월 — 벤치마크 대비 프로덕션 신뢰성 20-40% 과다 추정 (1차 출처: arXiv)
[5] Gartner, "Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026," 공식 보도자료, 2025-08-26 — 2027년까지 에이전트 프로젝트 40% 실패 예측, 멀티에이전트 문의 1,445% 급증 (1차 출처: Gartner 공식)
[6] LangGraph 공식 문서, "Human-in-the-Loop (HITL) Architecture," LangChain, 2025 — interrupt() 프리미티브, Static/Dynamic Async Interrupt 패턴, PostgresSaver/RedisSaver 체크포인터 (1차 출처: LangChain 공식)
[7] "Why Multi-Agent LLM Systems Fail," TianPan.co, 2025 — 14가지 실패 모드(시스템 설계 44.2%, 에이전트 간 불일치 32.3%); 조정 오버헤드: 5에이전트 200ms → 50에이전트 2초+ (T3 보조 참고)
[8] "생성형 AI가 IT 전략을 바꾼다 — 2026 IT 전망 조사 결과," CIO Korea (IDG), 2025-2026 — 국내 기업 70% 생성형 AI 투자, AI 에이전트 투자 우선순위 1위(63%), 도입 기업 38.1% 기대에 못 미침 (T2)
[9] "9 Strategies to Ensure Stability in Dynamic Multi-Agent Systems," Galileo AI, 2025 — 재시도 스톰: 서킷 브레이커, 하드 타임아웃 예산, 상관 ID 로깅 (T2)
[10] "Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems," arXiv, 2025년 12월 — "간헐적 성공은 불충분. 에이전트는 시간과 사용 시나리오 전반에서 안정적으로 수행해야 프로덕션 준비 완료" (1차 출처: arXiv)