
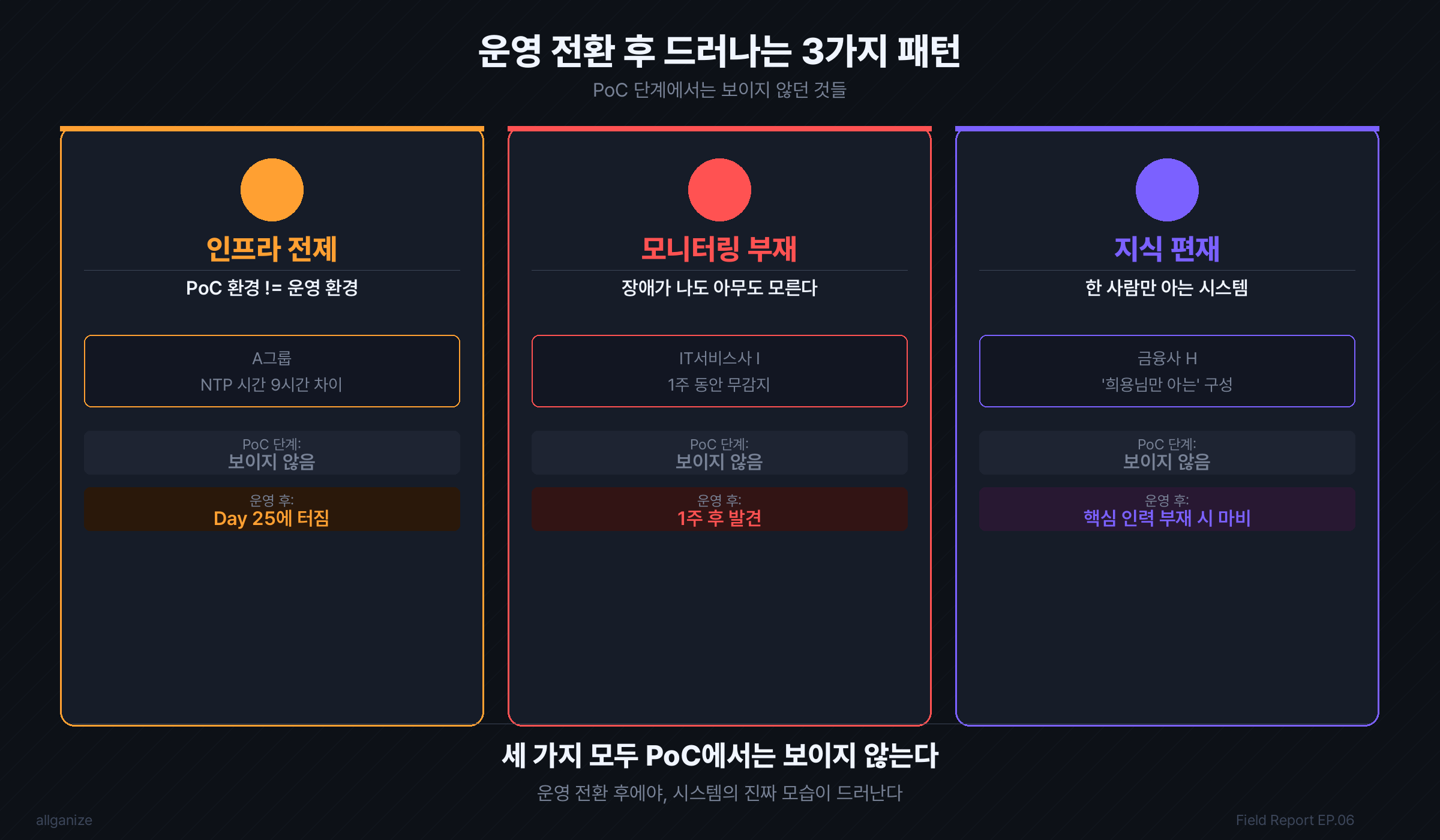
아무도 건드리지 않았는데 장애가 났다
PoC 너머, 운영이 진짜 시작인 이유. NTP·관측 부재·지식 편재 — 운영 첫 달에 드러나는 함정 3가지.
— PoC 너머, 운영이 진짜 시작인 이유
IT서비스사 I의 PMO 팀이 ArgoCD를 열었을 때, 상태 표시는 'Progressing'이었다.
개발망이 작동하지 않는다는 연락을 받고 확인한 것이었다. 이상한 건 타이밍이었다. 1주일 전, 다른 업무로 시스템에 잠깐 들어갔을 때도 같은 화면이었다. 그때는 "사용량 증가로 새로 뜨는 줄 알았다."
1주일 동안, 아무도 장애인 줄 몰랐다.
모니터링 대시보드는 없었다. 알림도 없었다. 누군가 들어가서 직접 확인하기 전까지는 아무것도 들리지 않았다. 시스템은 조용히 멈춰 있었고, 조직은 그 조용함을 정상으로 오해했다.
운영 전환의 첫 장애는 시스템 결함보다 관측 불능, 문서화 부재, 스코프 확장에서 시작된다.
지난 5편까지 이 시리즈는 한 가지 질문을 다뤄왔다. "어디서 깨지나, 어떻게 세우나." 이번 글은 그다음을 다룬다. 세운 뒤에 무슨 일이 벌어지는가. Gartner는 2027년까지 에이전트 프로젝트의 40%가 비용 상승, 불분명한 비즈니스 가치, 부적절한 리스크 통제 등으로 취소될 것으로 예측한다 [1]. Gartner가 지적한 '비용 상승·불분명한 가치·리스크 통제 실패'가 현장에서 어떤 형태로 나타나는지를 이 글이 보여준다.
서버를 재시작했을 뿐인데
금융 계열사 A그룹의 공통 업무 에이전트 시스템은 오픈 직후, 채 한 달이 지나지 않아 오후 중 장애 보고가 들어왔다.
"서버 재시작 후 k8s가 올라오지 않는다는 장애 보고 수신"
서버를 재시작했다. 그것뿐이었다. MicroK8S HA 클러스터 — 3개 Control Plane에 5개 노드로 구성된 환경이 전면 불능 상태에 빠졌다. Kubernetes API 서버가 no known leader를 반환하며 응답을 멈췄다.
원인은 두 가지가 겹쳤다.
첫 번째: dqlite Raft 쿼럼 붕괴. MicroK8S는 내부적으로 dqlite를 쓴다 [2]. Raft 알고리즘 기반의 분산 합의 프로토콜인데, 이 현장에서는 클러스터 노드 간 시간이 맞지 않아 리더 선출이 실패했다. 노드 간 NTP 시간 차이가 9시간 이상 벌어져 있었다. Raft 계열 합의 알고리즘은 리더 선출 타임아웃과 로그 복제 순서를 정상 범위의 시간 동기 위에 두고 설계되는 것이 일반적이며, 노드 간 시계 편차가 커지면 쿼럼 유지·리더 선출이 불안정해진다. NTP 자체는 IETF RFC 5905에 표준화된 시간 동기 프로토콜이다 [3].
두 번째: 수동 복구 시도가 문제를 키웠다. 초기 대응 과정에서 클러스터 상태 파일을 다루는 방식이 잘못됐다. 노드 식별자와 스냅샷 메타데이터가 맞지 않았다. 복구 시도가 클러스터 상태를 더 꼬이게 만든 셈이었다.
오전에 엔지니어가 현장에 나갔다
올거나이즈 FDSE 엔지니어가 다음날 오전 현장에 출동했다. 원격으로 해결할 수 있는 상황이 아니었다. 현장에서 직접 확인한 뒤, 방식을 정했다.
이미 꼬인 상태를 수습하는 것보다 노드를 클러스터에서 이탈시킨 뒤 깨끗하게 재진입하는 쪽이 빨랐다. 복구가 아니라 이탈 후 재진입이었다.
복구 완료 후, 재발 방지 작업이 시작됐다.
- NTP Slew 방식 시간 동기화 가이드 공식 문서화
- 단일 장애점 제거를 위한 이미지 레지스트리 이중화 구성
- 노드 간 시간 동기화 점검 절차 표준화
"서버 재시작이 클러스터를 죽인 것"이 아니었다. 서버 재시작이 그때까지 숨어 있던 NTP 불일치를 수면 위로 올린 것이었다. 운영 환경에서는 아무런 액션이 없어도 잠복해 있던 문제가 터지는 날이 온다. 이 클러스터는 오픈 직후 그 날이 왔다.
1주일 동안 아무도 몰랐다
IT서비스사 I의 PMO 개발망 장애로 돌아온다. 장애 그 자체보다 더 중요한 건 발견 방식이다.
ArgoCD에서 확인된 상태: Progressing. Argo CD는 애플리케이션을 두 축으로 관리한다 — Sync Status(Git 원본 매니페스트와 클러스터 실제 상태의 일치 여부)와 Health Status(실행 중 리소스의 건강 상태). 여기서 확인된 Progressing은 Health Status 축의 값으로, 아직 Healthy에 도달하지 못했거나 장시간 걸릴 수 있는 비-터미널 상태를 뜻한다 [4]. 즉, 진행 중인 것과 멈춰 있는 것을 이 값 하나만으로는 구분할 수 없다. 이 상태가 단순 딜레이인지, 실패인지, 배포 중인지 — 시스템 자체는 구분해주지 않았다. 운영팀이 직접 들어가서 확인하기 전까지는.
"PMO 개발망이 작동 안 된다고 연락이 와서 ArgoCD 들어가니 아래와 같이 Progressing 상태로 나오네요."
올거나이즈 엔지니어의 안내로 해결됐다. namespace 전체 restart. 특정 서비스만 문제라면 해당 서비스 안에서 sync → force replace 두 개를 체크하고 sync하는 방식.
복구는 빨랐다. 문제는 탐지에 1주일이 걸렸다는 점이다.
GPU 모니터링 없이 "느려진다"는 신고가 들어왔다
같은 구조의 문제가 다른 현장에도 있었다.
에너지 공기업 A사의 AI 시스템에서 "어제와 다르게 답변 속도가 매우 느리다"는 신고가 들어왔다. GPU 전력 불안정이 의심됐다. 그런데 엔지니어는 이 말을 해야 했다.
"GPU 쪽 모니터링을 하지 않아서 확인할 수가 없다."
느려졌다는 건 알았다. 왜 느려졌는지는 알 수 없었다. 모니터링이 없으니 추측만 남았다. GPU utilization 로그가 없으니 전력 불안정인지, 추론 큐 병목인지, VRAM 점유율 문제인지 — 아무것도 확정할 수 없었다. 이 상태에서 운영팀이 할 수 있는 건 재시작과 기다림뿐이다.
이 시점부터 권장하는 최소 구성은 단순하다. NVIDIA DCGM Exporter로 GPU utilization·메모리·전력·온도를 Prometheus에 수집하고, 추론 서버(vLLM·TensorRT-LLM 등)의 토큰 처리량과 큐 길이를 함께 Grafana로 시각화하는 것. 이 한 가지 파이프라인이 있어야 "느려졌다"는 신고를 받았을 때 전력 문제인지, 큐 병목인지, VRAM 압박인지를 5분 안에 좁힐 수 있다. 모니터링은 장애를 막는 도구가 아니라, 장애의 정체를 빠르게 좁히는 도구다.
이 두 사례는 다른 현장이지만 같은 구조를 공유한다. AI 시스템은 CPU나 메모리 서버와 달리, 이상 징후가 에러 로그로 드러나지 않는 경우가 많다. 응답이 느려지거나, 검색 결과가 달라지거나, 어떤 기능이 조용히 중단되거나. 이런 증상들은 누군가 직접 써보기 전까지는 포착되지 않는다.
4편에서 다뤘던 사일런트 장애 — "에러가 없는 에러" — 는 RAG와 에이전트 품질 레이어의 이야기였다. 이번 사례들은 한 단계 아래, 인프라 레이어에서 같은 일이 벌어지고 있음을 보여준다. 레이어가 달라도 구조는 동일하다. 관측 체계가 없으면 장애는 존재하지 않는 것처럼 보인다.
CNCF Observability Whitepaper는 관측성을 "시스템의 외부 출력만으로 내부 상태를 추론할 수 있는 능력"으로 정의하고, 이를 달성하는 신호를 로그·메트릭·트레이스 세 기둥으로 제시한다 [5]. AI 시스템에서는 여기에 GPU/추론 레이턴시·검색 정밀도 같은 도메인 지표가 더 얹혀야 한다. 세 기둥 중 하나라도 빠지면 — "응답은 있는데 왜 느려졌는지 모르는" 상태가 된다.
운영팀이 "이상 없다"고 말할 수 있으려면, 실제로 확인하고 있어야 한다.
안정화 직후 배포했더니 재현 불가 장애가 났다

제조사 E는 3편(GPU 최적화), 5편(MCP 연동)에 이어 이번이 세 번째 등장이다.
새 버전 배포 후 대시보드에서 SSO 로그인 루프가 발생했다. Works는 정상이었다. 대시보드만 문제였다.
롤백했다. 정상이 됐다.
원인을 찾으려 했다. 재현이 안 됐다.
"당시 우선 장애로 판단되어 롤백하는 부분에 우선순위를 두었다"
상황 판단으로는 맞다. 원인 추적보다 서비스 복구가 먼저다. 그런데 롤백 후 원인이 불명이면, 다음 배포가 두려워진다.
고객사의 한마디가 이 딜레마를 정확하게 담고 있었다.
"이제 막 안정화 되었는데, 또 배포하다가 장애발생 리스크가 있지 않을까 싶어서요 ㅠ"
프론트엔드 롤백, 그다음 백엔드 롤백 — 순서가 중요하다
SSO 로그인 루프의 구조를 뜯어보면 두 레이어가 얽혀 있었다. 프론트엔드 대시보드의 세션 토큰 처리와 백엔드의 SSO 콜백 엔드포인트가 새 버전에서 동시에 변경됐다. 어느 쪽이 루프를 만들었는지 로컬에서는 구분이 안 됐다.
현장에서 채택한 방식은 순차 롤백이었다. 프론트엔드만 먼저 이전 버전으로 되돌리고 — 로그인 루프가 해소됐다. 백엔드는 현재 버전을 유지했다. 이 결과가 의미하는 건 명확했다. 문제의 원인이 프론트엔드 쪽 세션 처리 변경이었다.
롤백 순서를 역으로 — 백엔드 먼저, 프론트엔드 나중 — 했다면 원인 추적이 훨씬 오래 걸렸을 것이다. 두 레이어가 얽힌 장애에서 격리 단위를 어떻게 잡는지가 진단 시간을 좌우한다.
원인을 확정한 뒤 논의는 다음 단계로 이어졌다. QA 환경과 프로덕션 환경의 분리 문제였다.
QA 환경이 프로덕션과 같지 않은 이유
PoC 기간 동안 가장 많이 듣는 말 중 하나가 "안정적으로 운영된다"는 확인 요청이다. 그런데 운영 전환 직후의 "안정화"는 사실 "큰 문제가 없었던 기간"에 가깝다. QA 환경이 프로덕션 환경과 완전히 일치하지 않고, 사용자가 적으며, 아직 발견되지 않은 엣지 케이스들이 존재한다.
제조사 E의 경우 QA 환경이 별도로 분리되어 있지 않았다. 스테이징 환경은 있었지만 스테이징 환경의 인증 설정이 프로덕션과 달랐다. 결국 새 버전의 SSO 처리 로직을 프로덕션 조건에서 사전 검증할 방법이 없었다.
이후 논의는 두 방향으로 갔다. 하나는 주말·늦은 저녁 시간대를 이용해 프로덕션에서 직접 재현을 시도하는 것. 다른 하나는 프로덕션 동등 QA 환경을 IT 인프라팀과 협의해 구성하는 것. 두 번째가 근본 해결이지만 시간이 걸렸다. 다음 배포 전에 원인을 확정하는 것이 목표였다. 원인 불명인 채로 다음 릴리즈를 올리면 — 또 롤백하게 될 수도 있고, 더 복잡한 문제가 섞일 수도 있다.
PoC 기간에는 "일단 된다"가 기준이었다. 운영 전환 이후에는 "왜 안 되는지 설명할 수 있는가"가 기준이 된다.
PoC에 없던 요구사항이 운영 시작 직후 추가됐다

금융 계열사 A그룹의 공통 업무 에이전트 시스템 WBS를 보면 패턴이 보인다.
PoC 기간에 합의된 범위가 있었다. 운영 전환을 준비하는 시점부터 그 범위가 달라졌다.
오픈 이전 약 한 달 시점에 "DRM 연동" 항목이 추가됐다. PoC 범위에 없던 기능이었다. 운영 환경에서 처음 요구가 나왔다. 문서 보안 솔루션이 AI 시스템이 생성하는 결과물에도 적용되어야 한다는 것을 — PoC 단계에서는 아무도 요구하지 않았다. 실제 사용자가 붙기 시작하면서 보안 담당자가 이 질문을 처음 꺼냈다.
오픈 후 약 6주 시점에 "시스템 안정화" 마일스톤이 신규 추가됐다. 오픈 전 계획에는 없던 마일스톤이었다. 실제 운영 데이터가 쌓이면서 안정화 작업의 필요성이 드러났다.
운영 전환 이후에는 개발 요청이 연이어 들어왔다.
- Agent Builder 이전 턴 메시지 필터링
- 공개 정보 검색 결과 content max length 제한
두 항목 모두 PoC 단계에서는 존재하지 않았던 요구사항이었다. 시스템이 실제 사용자와 만나기 시작하면서 나온 것들이다.
PoC 완료를 시스템 완성으로 보면 예산이 꼬인다
이게 A그룹만의 이야기가 아니다. 이 시리즈에서 다뤄온 고객사들 중 운영 전환 이후 WBS가 변경되지 않은 곳은 한 곳도 없었다. 인프라 요구사항이 추가되거나, 보안 정책이 붙거나, 사용자 피드백에서 나온 기능 수정이 들어왔다.
DRM이 빠져 있었다거나, 필터링 로직이 부족했다거나 — 이건 PoC 설계의 실패가 아니다. PoC는 실제 사용 전에 발견할 수 없는 것들이 있고, 운영이 시작되어야 비로소 드러나는 요구사항이 반드시 존재한다.
"PoC 완료 = 시스템 완성"으로 보는 조직은 이 시점에 당황한다. 추가 개발 요청을 "계획에 없던 일"로 처리하거나, 예산과 일정이 꼬인다. 반면 "PoC 완료 = 운영 데이터 수집 시작"으로 보는 조직은 이 확장을 정상 프로세스로 흡수한다. WBS가 바뀌는 것 자체가 문제가 아니다. 예상하지 못하는 것이 문제다.
"이 작업은 한 사람만 해봐서"

지식 편재 문제는 배포 이슈와 다른 형태지만, 같은 운영 취약성을 드러낸다.
금융사 H는 약 1년 후로 예정된 인프라 이전을 앞두고 있었다. 그 전에 실운영 데이터 백업 매뉴얼 요청이 들어왔다.
담당자 응답: MinIO 백업 롤백은 특정 인원만 해본 상황이어서, 그 인원이 절차를 알고 있을 것 같다는 답이었다.
고객사 자체 운영 전환 — PoC 완료 후 고객사 내부팀이 직접 운영하는 단계 — 을 준비 중이었다. 그 순간에 핵심 절차가 특정 개인의 머릿속에만 있었다. 인프라 이전이 1년 이상 남아 있었는데, 롤백 절차를 아는 사람이 한 명이었다.
이건 기술 문제가 아니다. 프로세스와 문서화의 문제다. 그리고 운영 전환 시점에 반드시 체크해야 하는 항목인데, PoC 단계에서는 좀처럼 점검되지 않는다.
"이 작업은 A님만 해봐서"라는 문장이 나오는 순간, 그 조직은 단일 장애점(Single Point of Failure)을 사람에게 두고 있는 것이다.
인프라 이전 전에 정리해야 할 것들
금융사 H는 이 인식이 나온 뒤 후속 작업이 빠르게 이어졌다.
그라파나 모니터링 미팅이 잡혔다. 현재 인프라에서 어떤 지표를 보고 있는지, 이전 이후 환경에서 동일한 모니터링 체계를 유지할 수 있는지를 정리하는 자리였다. 기존 그라파나 대시보드를 내보내는 것만으로는 충분하지 않았다 — 이전 환경의 스토리지 구조와 네트워크 설정이 달랐기 때문에 임계값과 알림 규칙을 처음부터 검토해야 했다.
파티션 구조 미팅도 별도로 진행됐다. MinIO 오브젝트 스토리지의 버킷 구조와 파티션 분리 방식이 이전 이후에도 동일하게 유지되는지 — 이전 과정에서 파티션 구조가 달라지면 기존 RAG 파이프라인의 경로 설정 전체를 재검토해야 한다.
백업 매뉴얼 작성이 시작됐다. MinIO 백업 롤백 절차를 담당 엔지니어가 처음으로 문서화했다. 이걸 기점으로 백업 실행 → 검증 → 롤백 테스트의 3단계 절차가 runbook 형태로 정리됐다.
이전 일정이 1년 이상 남은 시점이라서 다행이었다. 이 작업들이 이전 한 달 전에 시작됐다면 — 충분한 검증 시간이 없었을 것이다.
운영 전환에서 조직이 발견하는 세 가지

위의 사례들에서 반복적으로 드러난 함정은 세 가지로 나뉜다.
인프라 전제가 달랐다 — A그룹 케이스
NTP 동기화, 방화벽 설정, 포트 상태 — PoC 환경과 운영 환경은 같은 것처럼 보이지만 미묘하게 다르다. A그룹의 클러스터는 노드 간 NTP 시간 차이가 9시간이었다. PoC 기간에는 이 차이가 드러나지 않았다. 서버 재시작이라는 평범한 액션이 이 잠복 문제를 수면 위로 올렸다. 오픈 직후에.
운영 전환 전에 PoC 환경과 운영 환경의 설정 diff를 명시적으로 만들어야 한다. NTP 동기화 상태, 방화벽 규칙, 내부 네트워크 구성까지 포함해서. 이 문서가 없으면 장애가 나고 나서야 차이를 발견하게 되고, 장애 탐지가 지연되면서 MTTR(평균 복구 시간)이 늘어난다. 재발 방지 작업이 오픈 일정에 뒤늦게 끼어들면 서비스 가용성 지표 전체가 흔들린다.
관측 체계가 없었다 — IT서비스사 I·에너지 공기업 A사 케이스
AI 시스템의 이상 징후는 전통적인 서버 모니터링으로 포착되지 않는 경우가 많다. GPU 상태, 추론 레이턴시, RAG 검색 정밀도, 에이전트 응답 품질 — 이것들을 보는 체계가 없으면, 문제는 사용자가 신고하기 전까지 보이지 않는다.
IT서비스사 I는 ArgoCD 상태가 Progressing인 채로 1주일이 지났다. 에너지 공기업 A사는 GPU 모니터링이 없어서 레이턴시 원인을 추측만 했다. 두 사례 모두 "알람이 없으면 이상 없는 것"이라는 전제로 운영하고 있었다. GPU utilization, 추론 레이턴시 P95, ArgoCD sync 상태 — 이 세 지표가 Prometheus → Grafana로 연결되어 있고 임계값 알람이 붙어 있어야 비로소 모니터링이 있다고 할 수 있다. 이 중 하나라도 빠지면, 사용자가 체감하고 나서야 장애를 인지하는 구조가 되고, 사일런트 장애가 주 단위로 누적된다.
지식이 특정인에게 집중되어 있었다 — 금융사 H 케이스
PoC는 소수의 엔지니어가 집중적으로 구축한다. 운영 전환 시점에 그 지식이 문서화되지 않으면, 퇴사·휴가·조직 이동 시 공백이 생긴다. 담당 엔지니어 한 명만 알고 있는 MinIO 백업 롤백 절차는 운영 위험이다. 그리고 이 위험은 인프라 이전처럼 설정이 바뀌는 이벤트가 오기 전까지는 드러나지 않는다.
"이 절차를 나 말고 누가 실행할 수 있는가"를 각 운영 작업에 대해 점검해야 한다. 혼자만 할 수 있는 절차가 하나라도 있으면, 그 절차의 runbook 작성이 운영 전환의 선행 조건이다. 그렇지 않으면 담당자 부재 시 운영이 멈추고, 인프라 이전처럼 시간이 중요한 이벤트에서 일정 지연이 누적된다.
세 가지 모두 PoC 단계에서는 잘 보이지 않는다. 운영 첫 달에야 드러난다.
처음 보는 장애와 두 번째 보는 장애는 속도가 다르다

이 글에서 다룬 장애들은 모두 해결됐다.
A그룹의 클러스터는 복구됐고, NTP 동기화 가이드가 문서화됐다. PMO 개발망은 namespace restart로 재가동됐다. 제조사 E의 SSO 루프는 프론트엔드 순차 롤백으로 원인이 특정됐고 QA 환경 분리 논의가 이어졌다. 금융사 H의 인수인계 매뉴얼은 작성이 시작됐고 그라파나·파티션 미팅이 이어졌다.
빨랐던 이유는 기술이 아니라 현장 누적 경험에서 오는 속도다. 장애 이력이 쌓인 팀, 패턴이 내재화된 팀 — 이 두 조건이 운영 대응의 속도를 결정한다. 외부 벤더든, 내부 팀이든, 이 조건을 갖춘 쪽이 운영을 맡는 편이 안전하다.
A그룹 장애 복구에서 FDSE 엔지니어가 현장에 출동해 dqlite Raft 쿼럼 붕괴와 클러스터 상태 파일 충돌을 진단하고 이탈 후 재진입 방식을 결정하기까지 시간이 짧았던 것도, IT서비스사 I의 ArgoCD 문제에서 첫 응답이 "namespace restart"였고 "어떤 서비스만 문제면 sync → force replace"까지 바로 구분 안내가 가능했던 것도 — 모두 현장 경험이 패턴으로 쌓인 결과다. 처음 보는 장애는 원인 가설부터 세워야 하고, 두 번째 보는 장애는 해결책부터 꺼낼 수 있다. 그 차이가 1주일과 반나절의 차이다.
운영 파트너를 고를 때의 기준이 여기 있다. PoC를 함께 구축한 팀이 운영까지 보는 구조라면 그 패턴이 그대로 이어지고, 운영이 별도 조직으로 넘어가야 한다면 장애 이력·runbook·대응 패턴을 최소한 문서·훈련 형태로 이관하는 것이 출발점이 된다.
운영 전환 전에 반드시 확인할 3가지
아래는 CTO나 AI 도입 담당자가 "PoC 완료 → 운영 전환" 체크포인트에서 직접 물어봐야 하는 질문들이다. 추상적인 준비 여부가 아니라, 답이 나오지 않으면 전환을 미뤄야 한다는 기준이다.
1. 환경 설정 diff 문서가 있는가
"PoC 환경과 운영 환경의 차이를 나열한 문서를 지금 보여줄 수 있는가?"
대부분의 팀은 이 문서가 없다. 있다고 생각해도 NTP 설정, 방화벽 규칙, 내부 포트 오픈 현황이 포함되어 있지 않은 경우가 많다. A그룹처럼 NTP 차이가 9시간인데도 PoC 기간에는 드러나지 않는다. 오픈 후 첫 서버 재시작이 이 차이를 터뜨린다.
이 문서가 없으면: 운영 전환 전 엔지니어링 팀이 두 환경을 나란히 놓고 diff를 만드는 것을 선행 조건으로 건다. 하루짜리 작업이다.
2. 세 개의 모니터링 지표가 알람과 연결되어 있는가
"GPU utilization, 추론 레이턴시 P95, 서비스 sync 상태 — 이 세 가지가 임계값 초과 시 슬랙이나 PagerDuty로 알람을 보내는가?"
에너지 공기업 A사는 GPU 모니터링이 없어서 레이턴시 원인을 추측했다. IT서비스사 I는 ArgoCD sync 알람이 없어서 1주일 동안 장애를 몰랐다. AI 시스템의 장애는 서버 다운처럼 즉각 드러나지 않는다. 레이턴시 증가, 검색 정밀도 저하, 에이전트 응답 품질 하락 — 이것들은 알람 없이는 보이지 않는다.
이 세 지표가 Prometheus → Grafana → 알람 채널로 연결되어 있지 않으면: 전환 전에 구성한다. 이건 운영 환경 구성의 일부다, 부가 기능이 아니다.
3. 모든 핵심 운영 절차에 두 번째 실행자가 있는가
"MinIO 백업 롤백, 클러스터 재합류, 서비스 긴급 배포 — 각 절차를 혼자 실행할 수 있는 사람이 한 명 이상 더 있는가?"
금융사 H는 MinIO 백업 롤백이 담당 엔지니어 한 명만 알고 있었다. 인프라 이전이 1년 이상 앞인 시점에 이 사실이 드러났기 때문에 시간이 있었다. 그 사실이 이전 한 달 전에 드러났다면 충분한 검증 시간이 없었을 것이다.
핵심 절차의 두 번째 실행자를 지금 당장 물어보라. 답이 "그 사람이 없으면 못 한다"라면 — 그 절차의 runbook 작성과 교차 훈련이 운영 전환의 선행 조건이다.
6편을 마치며 — 운영은 구축이 끝난 뒤 시작된다
오픈한 날이 끝이 아니다. 구축은 만드는 것이고, 운영은 유지하는 것이다. 유지하는 일은 시스템을 처음 만들었을 때보다 훨씬 조용하게, 훨씬 오랫동안, 쉬지 않고 계속된다.
이 시리즈를 시작할 때, "AI를 기업 현장에 넣으면 생기는 진짜 문제들"이라는 말로 시작했다. 1편에서 6편까지 다룬 것들 — 배포 장애, 보안 설정, GPU 최적화, 사일런트 RAG 실패, 에이전트 체인 붕괴, 운영 인프라 — 을 통해 하나의 결론에 닿는다.
Gartner가 예측한 "40% 취소" [1] 중 상당수는 기술 부재가 아니다. 관측 부재, 문서화 부재, 운영 조건 부재에서 온다. 시스템은 작동하고 있다. 단지 아무도 보고 있지 않을 뿐이다.
지금 운영 중인 AI 시스템을, 누가 지켜보고 있습니까?
7편에서는 운영 안정화 이후의 이야기를 다룬다 — AI 시스템이 실제로 사용되기 시작할 때 조직 안에서 일어나는 변화들.
이 글의 사례들은 온프레미스 AI 구축 엔지니어링 팀의 운영 경험에서 추출했습니다. 고객사명과 담당자명은 모두 익명입니다.
운영을 함께 설계할 팀이 필요하신가요?
올거나이즈는 금융·제조·공공·IT서비스 현장에서 온프레미스 AI의 도입 검토 → 운영 전환 → 장기 운영 파트너십을 하나의 흐름으로 설계해 왔습니다. PoC 이후의 인프라 전제·관측 체계·지식 편재를 사전 점검하고, 운영 전환까지 함께 책임지는 구조로 일해 왔습니다.
- 아키텍처 리뷰 — 보유 인프라·NTP·네트워크·모니터링 상태를 놓고 운영 전제 조건을 점검합니다.
- 운영 전환 로드맵 — PoC 환경과 운영 환경의 diff·관측 3지표·runbook 요건을 하나의 문서로 정리합니다.
- 운영 파트너십 — 구축을 함께한 팀이 운영까지 연속해서 담당하는 계약 구조를 제안합니다.
출처
[1] Gartner, "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027," 공식 보도자료, 2025-06-25 — 비용 상승, 불분명한 비즈니스 가치, 부적절한 리스크 통제를 주요 취소 원인으로 제시 (1차 출처: Gartner Newsroom).
[2] Canonical, MicroK8s 공식 문서 — "High Availability" 및 "dqlite" 섹션: MicroK8s는 내장 데이터 저장소로 dqlite(Raft 기반 분산 SQLite)를 사용하며, HA 구성 시 3개 이상 Control Plane 노드로 쿼럼을 유지함 (1차 출처: microk8s.io/docs).
[3] IETF RFC 5905, "Network Time Protocol Version 4: Protocol and Algorithms Specification," 2010 — NTP v4 표준 규격. 분산 시스템에서 노드 간 시간 동기는 합의·로그 순서 보장의 기반 전제 (1차 출처: IETF).
[4] Argo CD 공식 문서 — "Application — Resource Health" / "Sync Status": 애플리케이션 상태는 Healthy / Progressing / Degraded / Suspended / Missing / Unknown로 분류되며, Progressing은 아직 Healthy에 도달하지 못한 비-터미널 상태로 정의됨 (1차 출처: argo-cd.readthedocs.io).
[5] CNCF TAG-Observability, "Cloud Native Observability Whitepaper," 2023 — 관측성 정의 및 로그·메트릭·트레이스 3대 신호 프레임, 도메인별 확장 지표 필요성 언급 (1차 출처: CNCF GitHub tag-observability/whitepaper).