Private AI Assistant: What "Private" Actually Means When You're Regulated
Enterprise RFPs say "private AI assistant" constantly, and the word does too much work. Three architectural layers — ingress, model operation, retrieval — and a decision framework for which layer your workload actually needs.
Private AI Assistant: What "Private" Actually Means When You're Regulated
A SaaS AI vendor was three weeks into a procurement cycle with a regulated bank. Their proposal said "private" four times on the first page. The technical evaluation went well. Then the bank's compliance team asked one question: "Where exactly is our query traffic terminated for inspection?" And the answer — a TLS-terminating L7 proxy, in front of inference, for rate limiting — disqualified the entire bid the same week. The vendor wasn't lying. They had simply not priced that proxy into their private story, because their other customers had never asked.
This is the kind of conversation we watch happen, in real time, when an enterprise RFP says "private AI assistant" and the vendor answers "yes, we're private."
The word does too much work.
Across 19 on-prem deployments we've taken from RFP to production — finance, manufacturing, public sector, healthcare — more than half had a first-integration meeting where buyer and vendor realized they meant different things by private. Not in bad faith. In the gap between an English word and an architecture. The fix is to stop treating "private" as one thing. There are three layers it can apply to, and the buyer's actual compliance bar usually requires two of them, sometimes all three. Most RFPs specify zero.
This post is the meeting where you and the vendor figure that out, written once. If your team is drafting an RFP right now, the practical version is at the end (§6, fifteen procurement-ready questions). The framework that gets you there is below.
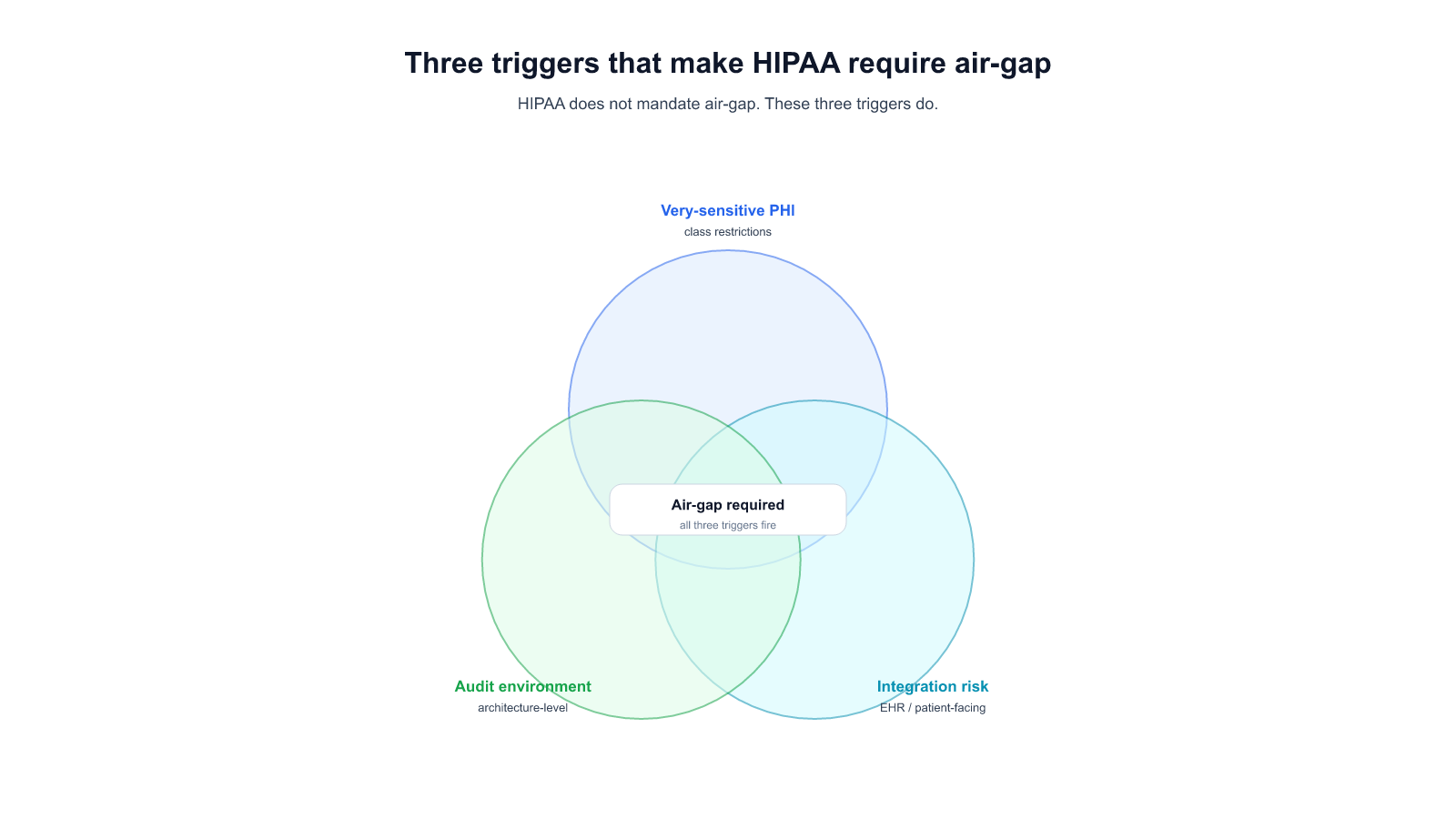
The three layers "private" can apply to, and almost nobody specifies all three
When a buyer says "private AI assistant," they usually mean one of three things, often two, occasionally all three — and the vendor has to ask, because the security posture is different at each layer.
1. Private data ingress. The documents, messages, and queries the user sends to the AI never leave the customer's network boundary in cleartext. This is the most common interpretation when a compliance team writes the RFP. It can be satisfied by an encrypted SaaS with a BAA, by a single-tenant hosted deployment with customer-managed keys, or by a fully on-prem cluster. Three architectures, same ingress story, very different other properties.
2. Private model weights. The model itself runs on hardware the customer controls. Nobody outside the customer's infrastructure sees what the model is responding, or at what volume, or how its latency behaves. This matters when the customer doesn't want a third party to build usage profiles of their internal work. SaaS can't satisfy this — even a BAA'd encrypted SaaS deployment gives the vendor operational observability into the model's traffic. Single-tenant hosted is partial. Full on-prem is the only complete version.
3. Private retrieval and memory. The corpus the AI grounds on — the internal documents, chat history, prior conversations — stays inside the network boundary and inside customer-controlled storage. It's never transmitted to a vendor-controlled vector database, never included in a model retraining corpus (deliberately or accidentally), never visible to the vendor's support team. This is where most SaaS AI vendors break for the strictest regulated buyers: the retrieval layer is where the most sensitive data sits, and the easy path for the vendor is to host the vector database.
Layer 1 in detail: private data ingress
Ingress is the easiest layer to say yes to and the easiest to get wrong. The test is: when a user types a query containing regulated data — a patient identifier, a draft earnings figure, a merger codename — can anyone outside the customer's control see that query in cleartext at any point between the user's keyboard and the model's GPU?
There are three architectures that credibly claim to pass:
Encrypted SaaS with a BAA and customer-managed keys. Vendor runs the inference in their cloud; traffic is TLS in transit; data is encrypted at rest with keys the customer controls. The BAA (or DPA, depending on jurisdiction) contractually binds the vendor to downstream handling. Satisfies most GDPR Art. 32 and HIPAA Security Rule §164.312(e) readings. Where it quietly breaks: any vendor-side observability that inspects plaintext — WAF with TLS termination, a debug dashboard support engineers use when a ticket comes in, log scrubbing that sometimes misses. We've watched a SaaS AI vendor discover, during a customer audit, that their "encrypted end-to-end" flow had a TLS-terminating L7 proxy in front of the model for rate limiting and anomaly detection. The customer's compliance team disqualified them the same week. The vendor wasn't lying — they had just not priced the proxy into their encryption story.
Single-tenant hosted in the customer's cloud account (BYOC). The vendor's control plane lives in its cloud; the data-plane inference runs on a cluster inside the customer's AWS or GCP account. Traffic stays within the customer's VPC; the vendor's operators don't have console access to the data plane. This is a clean fit for buyers who want "private data, but I don't want to run GPUs in my own datacenter." It fails the bar when the customer's regulation forbids data residency in specific cloud providers (some EU sector rules), or when the vendor's control plane requires egress for telemetry and that telemetry path is not auditable.
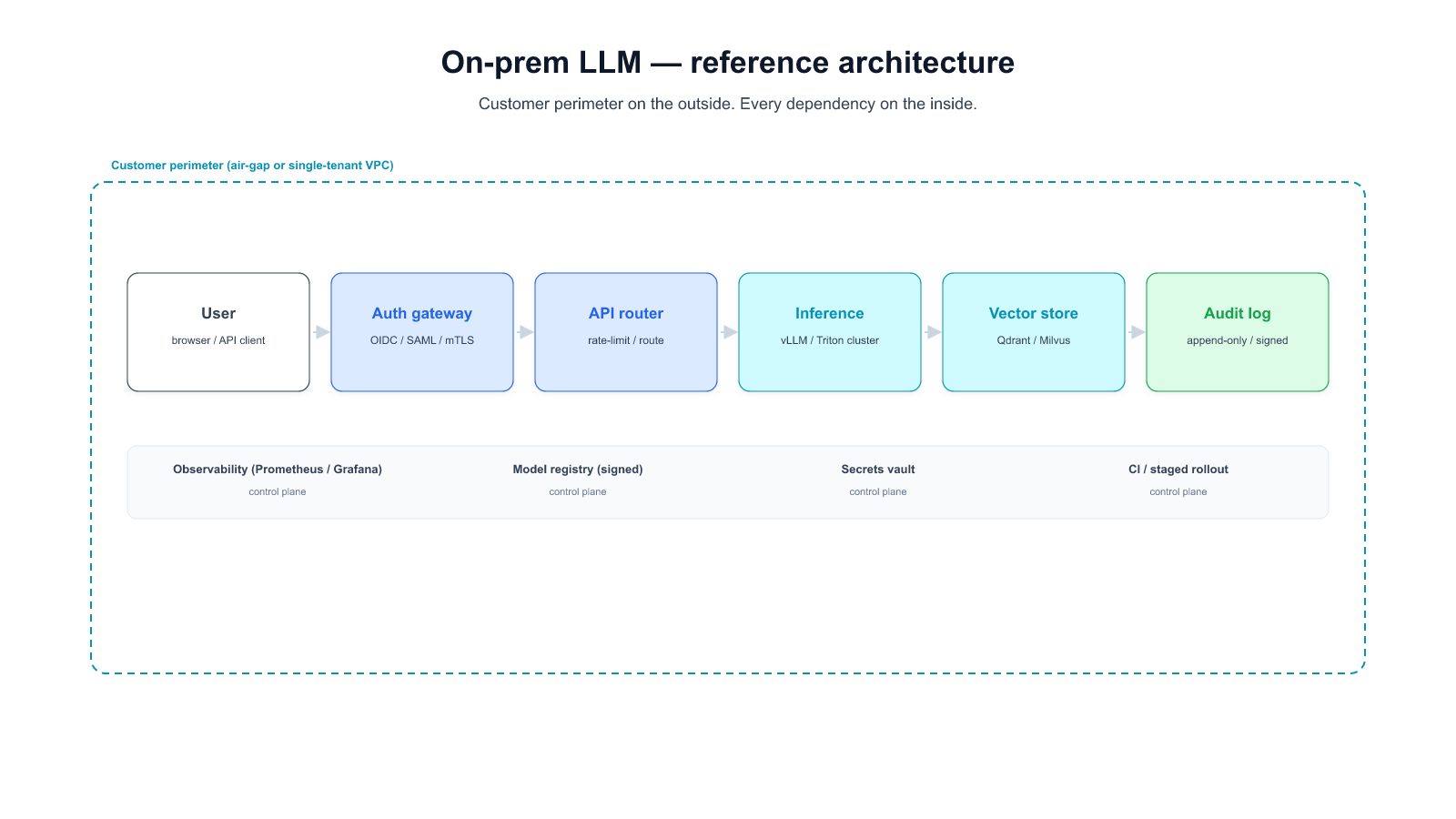
Fully on-prem or air-gap. Inference runs on hardware the customer owns, in a network segment that has no path to the internet. Ingress is by definition private — there is no third-party network between the user and the model. This is what forced sectors (public sector, some banking, defense contractors) end up with when no egress at all is acceptable. The cost is the rest of this post's subject.
Which regulations force which bar at ingress: GDPR Article 32 permits the encrypted-SaaS architecture if the encryption + contractual controls are documented and the data-transfer mechanism (SCCs, adequacy decision) is valid. HIPAA's Security Rule and Privacy Rule can be satisfied by encrypted-SaaS + BAA for most covered entities. Korea PIPA (personal info) — similar, though cross-border transfer rules tighten for sensitive categories. Where encrypted SaaS stops passing: certain national security contexts, classified data environments, some AISI (Japan AI Safety Institute) guidance for regulated sectors, and any customer whose auditor evaluates architecture rather than outcome (covered in the decision framework in §5 below).
Layer 2 in detail: private model weights and private operation
A more subtle bar. Even if a query's cleartext never leaves the customer's network, the operational metadata of running a model — query volume, latency distributions, error rates, feature-usage patterns, which users query which topics — can leak a lot about what's happening inside the customer's organization.
Two concrete examples of why this matters in regulated settings:
- A bank's M&A team running an AI assistant over internal deal documents. Even with queries encrypted, a SaaS vendor's operational telemetry sees the volume spike when a deal goes live, the latency tail change when larger documents get ingested, the new user accounts created the week an acquisition target is signed. That's MNPI-adjacent signal, leaking to a third party that didn't sign a securities NDA.
- A pharma R&D team querying a model on competitor clinical-trial documents. The content of the queries is the point — but so is the rate of queries, which correlates to drug-candidate evaluation pace. A vendor with telemetry visibility onto a pharma customer is effectively a research-timeline leak channel.
These aren't content breaches. They're pattern breaches. And most SaaS AI contracts don't even mention operational pattern data, because it's not considered "customer data" in the traditional sense.
Three architectures at this layer:
- SaaS. Fails, structurally. Even with the strongest encryption-at-rest and cleartext-never-leaves-our-boundary story, the vendor's inference cluster sees every query arrive, sees its latency, sees which authenticated user sent it. That operational observability is the service. You can't buy it away.
- Single-tenant hosted (BYOC). Partial. The data-plane inference is inside the customer's VPC so query content and latency are opaque to the vendor. But the control plane — authentication, billing, model-version management, feature flags — typically calls home, and the telemetry that enables the vendor's operations team to debug production issues usually includes anonymized-but-correlatable usage data. Carefully configured, this can get close to complete. Most deployments we've seen don't configure it that carefully out of the box.
- Fully on-prem or air-gap. Complete. Operational metadata stays with the customer's ops team. The vendor gets what the customer chooses to share at the support-ticket level and nothing else.
Which regulations force this bar: MNPI-handling obligations under FINRA / SEC for financial firms. Trade-secret protection frameworks when R&D patterns count as trade secrets. NIST AI RMF's MEASURE and MANAGE functions place operator visibility inside the customer's responsibility — if that visibility is outsourced to a vendor, the customer has de facto outsourced part of their compliance posture, which most AI RMF audits flag. Japan AISI draft guidance for the financial sector treats operational observability as part of governance scope explicitly.
The short version: if your buyer's compliance team cares about who sees patterns, not just who sees content, Layer 1 is not enough and Layer 2 becomes a real requirement.
Layer 3 in detail: private retrieval and memory
The retrieval layer is where the most sensitive data usually sits. An AI assistant in an enterprise context isn't useful without access to internal documents — policies, contracts, customer records, engineering docs, deal rooms, medical files. Every retrieval-augmented generation (RAG) pipeline has three places where that corpus can leak:
1. The embedding step. To turn documents into vectors the retrieval layer can search, something has to run an embedding model over each chunk of each document. If that embedding call goes to a vendor-managed embedding API, slices of your sensitive corpus have just been sent out — one API call per chunk, potentially millions of calls. Most SaaS AI products quietly use OpenAI, Cohere, or an internal equivalent for embeddings. The customer's document content crosses the boundary chunk by chunk. This is frequently not discussed in the sales cycle because "only embeddings" sounds harmless. Embeddings are inversion-susceptible — research over the last two years has shown that embeddings can leak original text with a non-trivial reconstruction rate. For regulated content, treat embeddings as sensitive as the source text.
2. The vector store. The database that holds the embedded chunks. If it's hosted by the vendor, the customer's entire embedded corpus is now sitting in a third-party service that is not in the customer's audit scope, not included in the customer's incident-response plan, and often not tied to a specific data-residency region the customer's regulation requires. GDPR Article 17 right to erasure becomes contractually possible but operationally opaque when the vector store is vendor-managed — deletion requests depend on the vendor's pipeline, not the customer's. HIPAA's de-identification standard is near-impossible to apply to a vector DB because the vectors retain the re-identifiable information by design.
3. Logs, support access, and retraining. Retrieval results are a gold mine of insight into what a customer is working on. Support engineers debugging a quality issue routinely look at query-retrieval-response traces, which contain snippets of the retrieved documents.
A specific scenario we've watched play out: a healthcare customer files a quality-regression ticket against a SaaS AI vendor. To diagnose, the vendor's support engineer pulls a sample of recent retrieval traces from production logs — standard ops practice. The traces include verbatim chunks of patient records, because the corpus is the EHR. The support engineer is in a different jurisdiction than the patients. The customer's BAA covers data processing and storage. It does not cover vendor support staff in jurisdiction X reading PHI in jurisdiction Y for ticket triage, because the contract was written before anyone modeled retrieval-trace exposure. By the time legal flags this, the engineer has resolved the ticket and the trace samples are sitting in the support tool's history for 90 days. There is no breach to report under any rule that names retrieval logs. There is also no answer to "how do we make sure this doesn't happen again" that doesn't change the architecture.
"Do these logs feed the vendor's next model generation?" is a separate, equally consequential question that most AI SaaS contracts give a deliberately ambiguous answer to. The honest answers range from "no, fully isolated" to "anonymized-but-retained for up to 12 months" to "used in a training mixture with consent assumed via ToS." None of these is acceptable for a corpus that contains PHI, MNPI, or trade-secret material; some are acceptable for general operational logs.
Architecture mapping at this layer:
- SaaS. Fails this layer structurally for strictly regulated corpora. Even a vendor that does the embedding inside your VPC (some do) typically stores the vectors in their managed service.
- BYOC. Can pass cleanly if the customer insists on: embedding model running inside their VPC, vector DB running inside their VPC, no retrieval logs egressing the VPC. Few default deployments are configured this way. Most need explicit customer-side engineering work and a vendor's blessing on a non-default topology.
- On-prem. All three sub-layers stay with the customer by default. The retrieval corpus never leaves the boundary. Audit scope is clear. Erasure is a local operation.
Regulations forcing Layer 3: HIPAA Privacy Rule + Security Rule for PHI in retrievable corpora; GDPR Article 17 for EU personal data (especially sensitive categories); FINRA / SEC record-keeping rules for broker-dealer communications; trade-secret protection frameworks where a corpus is the trade secret (internal R&D, legal work product, M&A deal rooms). And for anything that might contain payment card data, PCI DSS scope expands to include the vector store — most SaaS vendors will not accept PCI scope, which forces customers off the SaaS path for those workloads.
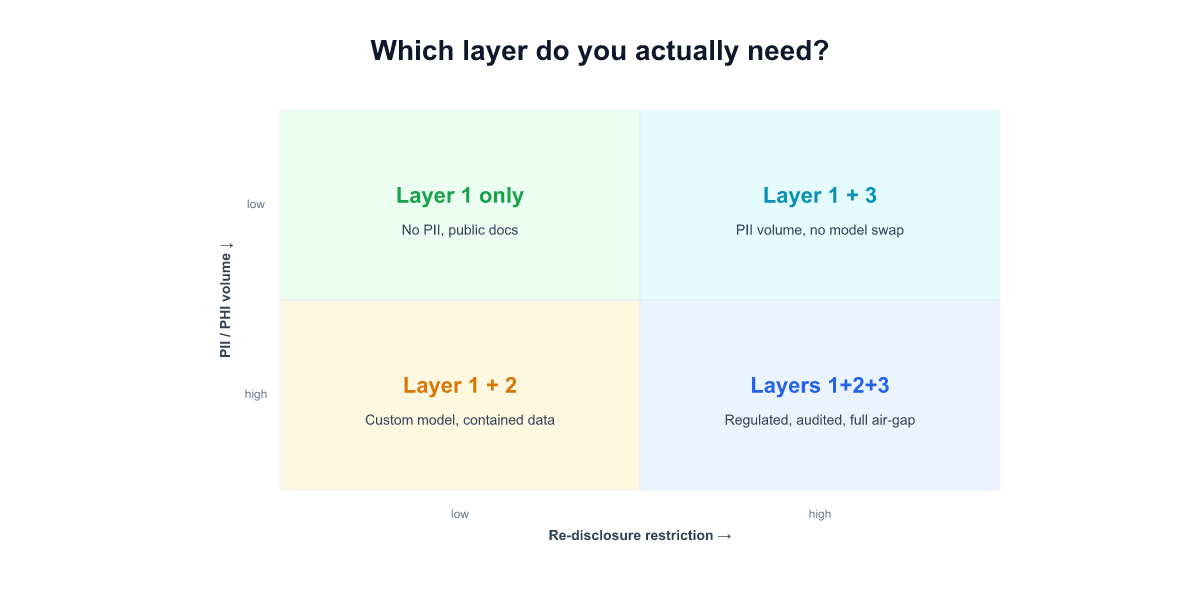
Which layer do you actually need? A decision framework
Three layers are strictly nested: if you need Layer 3, you also need Layer 2 and Layer 1; if you need Layer 2, you also need Layer 1. The question is where the bar sits for a specific workload. A rough framework:
Layer 1 only is enough when: - The regulated data is content-sensitive but not pattern-sensitive (e.g. some HIPAA use cases in provider-facing administrative tooling) - The vendor's BAA, encryption posture, and data-transfer mechanism (SCCs / adequacy decision) are documented and pass a standard audit - Your auditor evaluates outcome (did encryption hold? did access controls work?) rather than architecture (what's physically where?)
Layer 2 is required when: - The use case exposes operational patterns that are themselves sensitive — M&A, R&D timing, deal-room activity, investigative workflows - Your sector regulation includes explicit operator-visibility requirements (FINRA for financial firms, NIST AI RMF for US federal suppliers, AISI draft guidance for Japan financial sector) - The vendor's operations team cannot lawfully be in scope for your data's pattern surface
Layer 3 is required when: - The retrievable corpus contains PHI, PCI-scoped data, personal data categories from GDPR Art. 9, or trade-secret-grade material (deal rooms, clinical trial docs, legal work product) - Your compliance framework audits architecture — "show me the physical boundary of this data" — not just outcomes - Your regulator has explicitly forbidden a specific cloud provider or geography for the corpus (some EU banking, some Korean public sector, some defense)
When Layer 3 is required but air-gap isn't: BYOC can satisfy it, but only with explicit customer-side engineering — embedding model inside the VPC, vector DB inside the VPC, retrieval logs not egressing, and a vendor contract that disallows default telemetry from the retrieval layer. Ask for the deployment diagram. Don't accept a product-tier name.
When air-gap is the only answer: sectors where any egress is prohibited (classified data, some defense contractors, specific national-security contexts) and sectors where the auditor requires a physically-isolated network segment regardless of the vendor's encryption posture. If you're not in one of these buckets, air-gap is a choice, not a requirement — and the recurring cost (covered in [[023]]) is real.
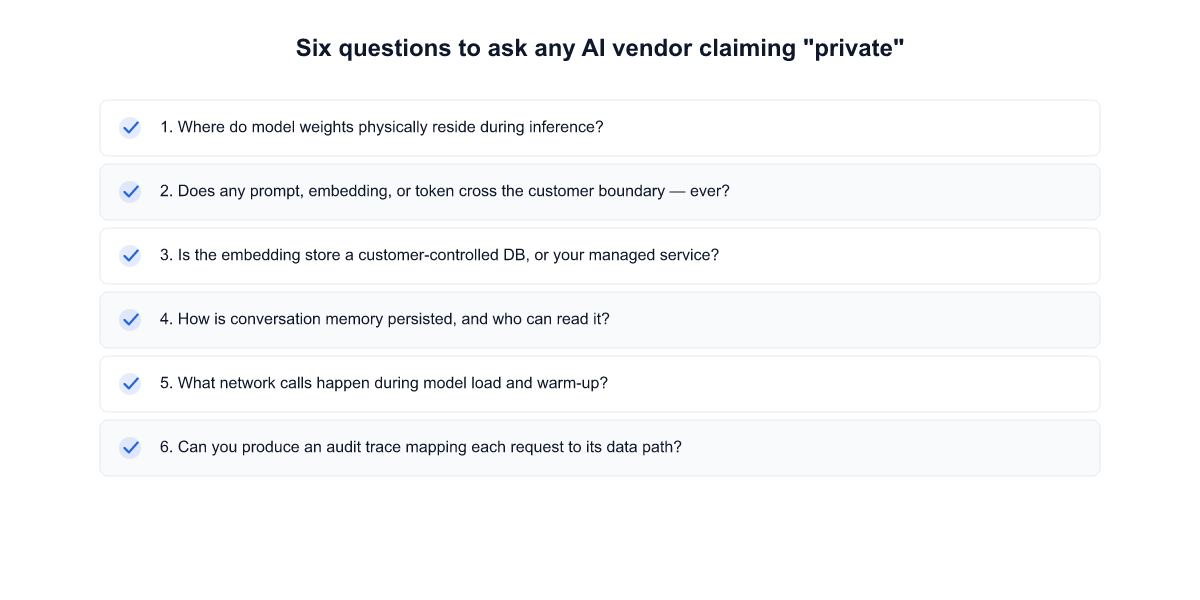
What to ask your AI vendor, specifically
Procurement-ready questions. They're not marketing questions. They're operational questions. Ambiguous answers are signals.
- Where does embedding happen? Which service, which region, which provider? Is it on our side or yours?
- Where is the vector database hosted? What region, what jurisdiction, who has operational access?
- What retrieval logs do you keep, for how long, and who on your side can read them? Is the access to those logs audit-logged in a way we can read?
- Do retrieval logs feed model training — yours or any subcontractor's? Under what consent model?
- What control-plane telemetry leaves our VPC? Is the set of fields, frequency, and destination documented we can subscribe to an alert when it changes?
- Can a support engineer see my query contents or retrieval results during ticket debugging? Is that gated by customer consent per-ticket?
- What happens to our embeddings and vectors when we upgrade the model? Do embeddings regenerate, in which case documents cross the boundary again?
- Exit and erasure: if we give 90 days' notice and terminate, what's the runbook and timeline for every copy of our data (primary store, vector DB, logs, backups, analytics pipeline)?
A vendor who answers these quickly and concretely has built for this buyer segment. A vendor who hedges, or routes the questions to "our legal team," or says "depends on your configuration" without saying which configurations are available, has not.
The one-sentence version
"Private AI assistant" means three different architectures depending on which layer of private the buyer actually needs. Deciding which layer applies to your workload — and writing that into the RFP — saves weeks of back-and-forth during vendor selection and avoids a disqualification after a year of implementation.
If you're at the RFP stage and unsure which layer your regulation actually requires, we'd rather talk through it with you than have you pick the wrong one.
If this is on your shortlist, we'd like to hear the specifics.
Start a conversation — tell us about your deployment model, compliance constraints, and timeline. We'll come back with a specific take, not a generic follow-up.
Start a 14-day trial — run Alli Coworker against your own documents and workflows before you commit.